#8 Compiler & Architecture
前言
计算机体系结构是非常复杂的学科方向,大部分人在学习的路上都会遇到很大困难、不解。因为计算机体系结构涉及的面实在是太广了,从门电路到晶体管,到计算机部件的设计,再上升到软件层面的编译器和操作系统,你需要培养自己的软硬协同的思想,对各个方面可能都需要有一个系统的认识与了解,毕竟软件的很多设计与问题都是需要在对硬件的了解下才可以清楚的。但知识永远是可以学会的,不要对知识保有畏惧心理,请相信自己,别人可以做到的你一样可以。
Compiler是计算机体系结构学习中很重要的部分,对Compiler的学习,可以对你思维方式进行很大程度的提升,并且在对Compiler的后端架构与寄存器的考量更是对你体系结构学习的一个重要考核。
下面的所有题目只是计算机体系结构的冰山一角,如果你阅读完整个题目后觉得自己对于这个方面非常感兴趣,可以到 CS自学指南 进行更深入的学习,或者通过招新题进入工作室的方式获得学长更加细致化的指导(墙裂建议)。下面的所有题目并不要求全部做完,你的努力我们都看在眼里(看在你的md文档里),所以不论题目完成到什么程度,请务必将你的学习过程和目前进度发送给我们,Respect!
这个难度并不是依次递增的,只是按照编译的一个基本流程去出题的,所以有做不出来的题目可以试着往后面做(加油!!!)
开始
Compiler 之旅是一段漫长且艰辛的旅程,我周围有很多人选择做这个,也有很多人放弃了,对我而言,就是一点点做了做,最后发现也没有那么难,最后就做了出来,可能很多时候就是这样的,需要我们先勇敢迈出第一步去做一下…
当然,我希望自己可以做一个好的引路人,可以方便容易的让你对Compiler有一个入门…
Compiler
让我们以小谢的身份进入这场 Compiler 之旅。
在学习任何新的东西之前,如果能够先整体了解一下,那就是个不错的开始,Compiler的学习自然也是如此。对于新人小谢来说 CS 143 Compilers … 这个未免也晦涩与枯燥了吧,小谢继续寻找着,直到发现 编译体系漫游, 内心os:实在讲的太好了捏,图文并茂,墙裂推荐。
TASK0
看完上述科普向视频,并借助AI工具,相信你能记下了大量的笔记,大概能对编译器是干嘛、编译的流程、现在市面上有哪些编译器(编译器框架)有一个大概的了解,请在你的提交文档中包含但不局限于以下几个问题:
- 什么是编译器?编译器的大致工作流程是怎样的?
- LLVM 编译器的架构是怎样的?
- 编译器中端的主要任务是什么?
TASK1
学习编译的最好方式当然是 (os:直接套用别人的项目 )自己动手写一个编译器,但是从0实现一个完整的编译器又是一个任务量巨大且十分困难的工程,更不要说实现一个优化性能超强、拓展性极好的编译器了。一般来说,大家编译器入门的第一个小项目应该是实现一个支持四则运算的编译器,这其中涉及到根据我们所给定的文法来实现特定的功能。
考虑到实现难度问题,当然是不会让你手搓编译器前端滴,那简直是效率又低,而且在工业界也是使用成熟的工具进行处理。
我们需要依托Flex、Bison工具来完成我们的编译器。
在开始之前,你需要了解:
- 什么是Flex、Bison?
- 什么是文法,有哪些文法?
要求实现:
- 实现支持加减乘除,逻辑运算的整数计算器,实现正确的计算优先级 (经典中的经典)
- 正确实现优先级 例如
4 * (6 - 2)
- 根据下面的表达式拓展Flex、Bison程序
- 注意特殊情况,例如:与 0 相关
实现下列的表达式:
(a ++ b) ::= a + (b + 1)
(a &* b) ::= (a & b) * b
(a |* b) ::= (a | b) * b
Eg:
输入:1 -- 2
输出:-1
选做内容:
参考资料:
自己动手写编译器
Flex与Bison中文版电子书
Flex与Bison使用教程
Flex
Bison手册
Task2
小谢同学顺利的完成了 Task1 的任务,发现flex,bison 起到了词法分析与语法分析的作用,小谢接着了解了LLVM项目后面流程,发现LLVM 的项目会生成中间代码 IR (Intermediate Representation),这里面的学问就大了,让我们跟随小谢同学一步步往下开展:
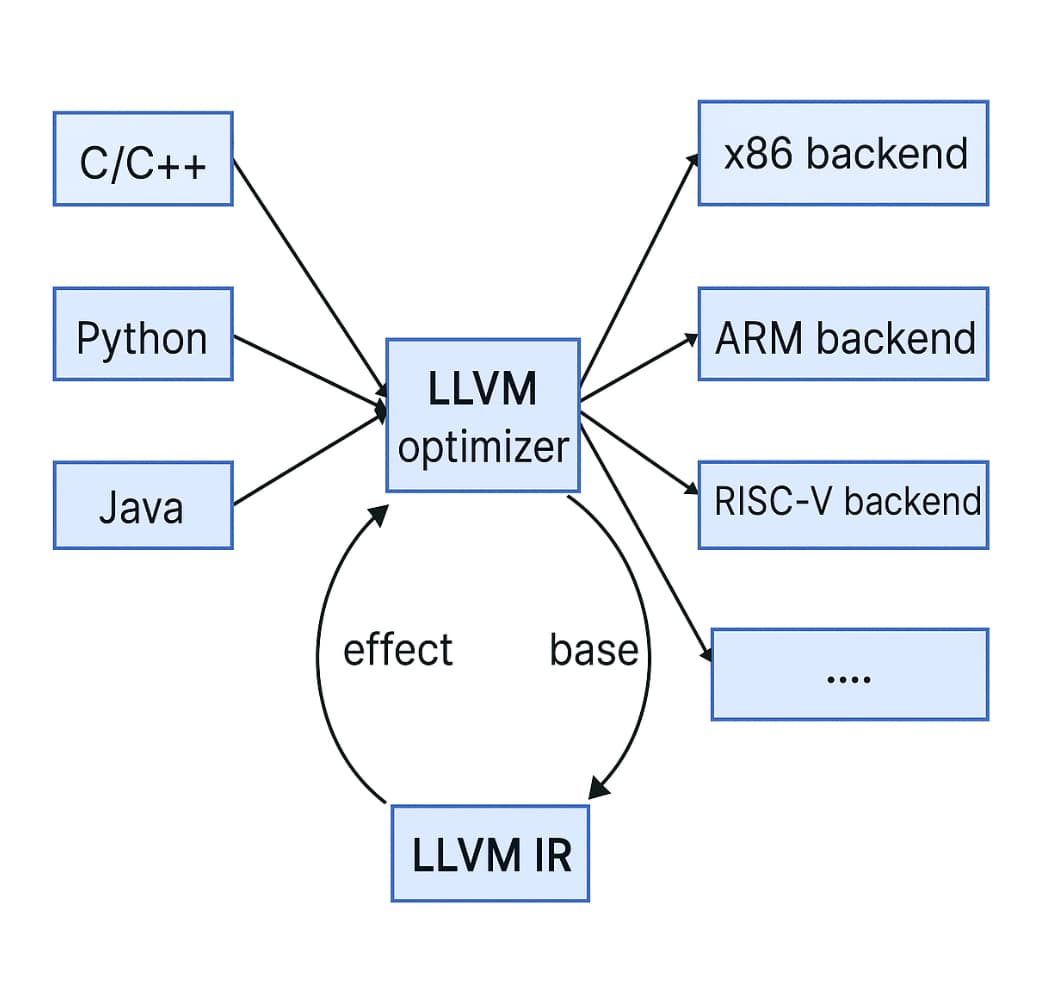
LLVM IR
首先小谢同学思考这个IR存在的意义是什么,明明可以直接从C语言一步步映射到目标的架构例如 RISC-V指令,那为什么还需要存在一个中间 IR 来将 C语言先转化成 IR 再翻译成 RISC-V 指令呢?小谢同学又多想了其他的语言以及后端架构,假设 C,Rust,Java语言到后端的MIPS,ARM,RISC-V,那么就是 C → MIPS , C → ARM, C → RISC-V, Rust → MIPS… 共是九种,而如果有中端架构 IR 存在的话,任何的语言都需要先转化成中端架构 IR 再转换成后端的汇编指令,相乘的关系就变成了加法,所以 C,Rust,Java → IR → MIPS, ARM, RISC-V 就是 3 + 3 = 6 种的情况存在。
IR的存在可以避免转化的时候写很多重复冗余的结构,当然IR也是存在很多其他好处的,我们之后也会讲解到的。
要求:
- 了解 LLVM IR的一些基础语法 (建议把Task 2 读完再同一做)
- 了解一些 MLIR (选做,但强烈建议了解一下)
SSA (Static-Single-Assignment Form)
SSA 是 IR 的一种属性,要求每个变量仅被赋值一次并且再被使用前定义。(其实核心思想就是确保每个变量只被赋值一次),举个例子就好理解了
1: x = 1;
2: y = x + 1;
3: x = 2;
4: y = x + 1;
5: return y;
这个代码转化为 SSA 的形式就变成了
1: x1 = 1;
2: y1 = x1 + 1;
3: x2 = 2;
4: y2 = x2 + 1;
5: return y2;
这个 x1,x2 相当于对 x 有了版本的控制,将原本 x 的生命周期进行了重新划分,本来x的生命周期从 1 到 4 ,而进行了SSA 的转化 x1 的生命周期是 1到 2, x2 的生命周期是 3到 4。因为在 3 语句处 x 被新的值进行了重新的定义,所以此时的 x 和前面的 x 其实可以不算是同一个 x ,才进行了新的 def 。
那这样做有什么好处呢?
对优化的进行做深厚的准备。(好像等于没说
其实编译器有中端这个概念,并且发展到现在的形式,最最具有革命性的突破是1991年静态单赋值形式(SSA Form)的引入。明明只是简单的约束条件(确保每个变量只被赋值一次)却带来了十分深刻的影响。
SSA 的东西其实还有很多需要讲的,剩下的就要交给小谢自己了。
学习链接: 第一章:编译与静态代码分析概论 | SSA.to
你会在很多网上链接中找到答案,我给你的仅仅可以做一个参考
要求:
- 上网再查询资料,谈谈自己对 SSA 的了解
- SSA有很多其他的形式与变种,去了解一下呢
- 到目前为止,是不是有些情况的代码, SSA 是无法转化的呢 (思考ing …)
Value, Use, User
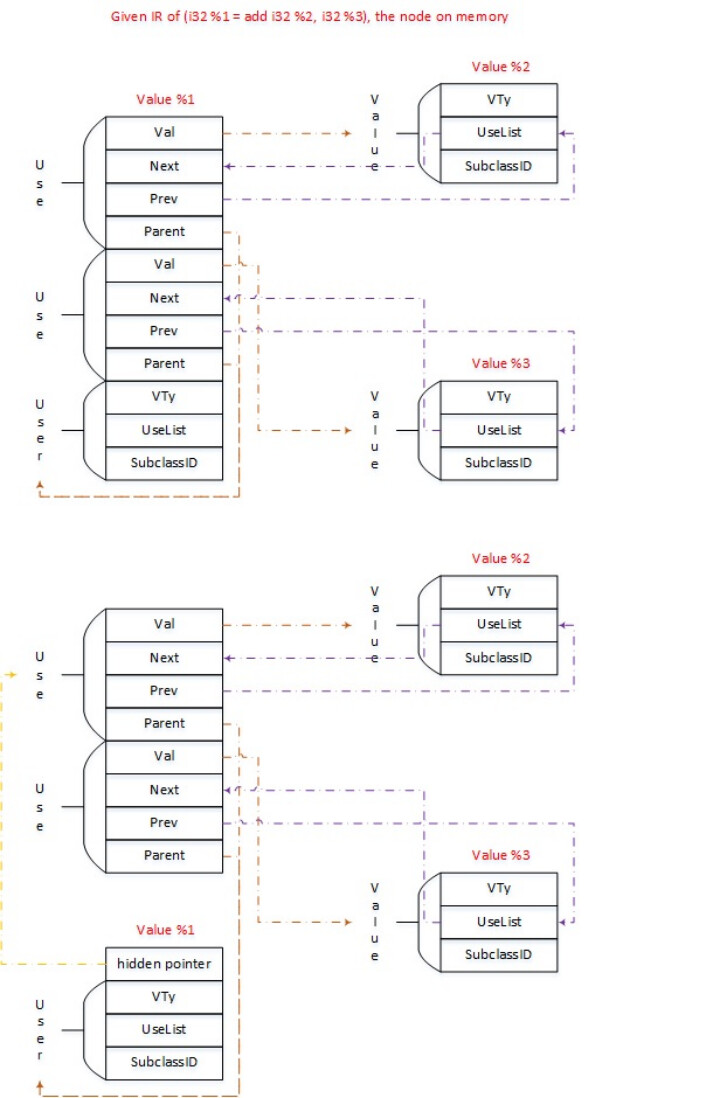
小谢同学接着学习LLVM 项目,他听到了 “LLVM 中一切皆 Value”的这样的话,注意到了 Value,Use,User 这样的 class 类,并且对此产生了浓厚的兴趣…
这部分应该是 LLVM中很核心与关键的部分了,因为存在 这样的关系才使得很多的优化可以得以施行
(老图常用了属于是)
这里举一个例子来帮助大家更好的理解这样的关系。
int main()
{
int a = 10;
int b = 20;
int c = a + b;
return c;
}
define i32 @main(){
.0:
%.7 = alloca i32
%.4 = alloca i32
%.1 = alloca i32
store i32 10, i32* %.1
store i32 20, i32* %.4
%.8 = load i32, i32* %.1
%.9 = load i32, i32* %.4
%.10 = add i32 %.8, %.9
store i32 %.10, i32* %.7
%.12 = load i32, i32* %.7
ret i32 %.12
}
相信你对 LLVM IR 已经有了一定的了解,alloca 语句就是开辟内存,store 存储值到对应的内存地址,load便是从对应的地址中将值加载出来。(这个其实也是一个难点)
我们重点看一些 %.10 = add i32 %.8, %.9 这行指令,%.10 是一个 User(使用者),它使用了两个 值 %.8, %.9 ,(被使用者);在内存中如何建立这种使用与被使用的关系呢?当然是大一上所学习的数据结构。嗯,还需要注意的是 %.8 (被使用者)在 %.8 = load i32, i32* %.1 语句中,又是一个 User(使用者)了。所以一个值既可以是使用者也可以是被使用者,如果一个类中我们可以存储它的使用者,也要存储它的被使用者,那这个变量的定位就是那么那么清晰了。
当然,前面我只是笼统的在说,如果你也想要了解这个数据结构,下面任务可能会帮助到了。
深入浅出 LLVM之 Value 、User 、Use 源码解析 13
对于LLVM之类的编译器是如何实现在构造 SSA 形式的 IR 的时候,计算出 def-use 链? - 知乎
GitHub - bigSheep123/JoTang_Compiler: To recruit new members for Caramel (一个 Value,User,Use 实现的小模型)
https://github.com/llvm/llvm-project.git(llvm 源码 低版本的就好,2.7左右,不强制一定阅读)
要求:
- 阅读上面的文章,以及找各种资料,理解Value,Use,User这一套数据结构
- 阅读小模型的代码,谈谈小模型是如何实现Value,Use,User这一套的,你之后也会实现的(
- 选择(不)阅读 llvm 源码,编译 llvm 源码 (选做)
BasicBlock && CFG
小谢在学习了 Value,Use,User 之后对简单的 IR 代码有了很深刻的认知,但是他发现LLVM项目中的包含链实际上很长 Value → User → Instruction → BasicBlock → Function → Module … 他想继续往后面去了解更多,当然了包含链不止这么一条,其实还有很多,很复杂(
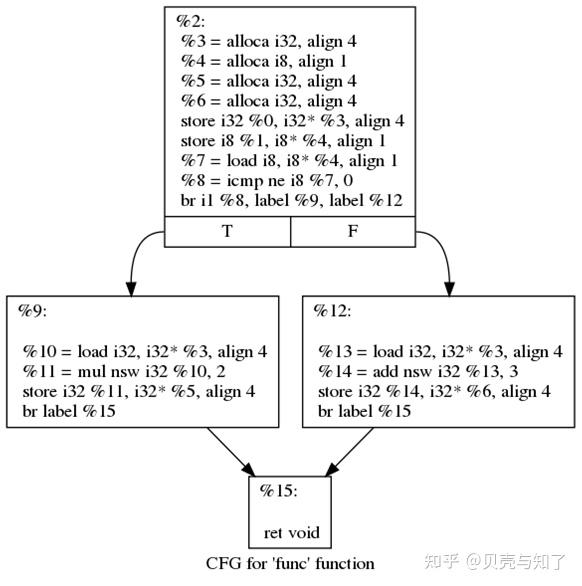
下图是一个对 IR 的 .ll 文件的一个划分:
(opt -dot-cfg xxx.ll) 获得一张图片
(截自 知乎 贝壳与知了用户,因源链接已经失效 特此说明)
看上图可以很清楚的看到,函数中存在很多的基本块(BasicBlock)
通过划分基本块,就可以得到 CFG (control flow graph) 控制流图。
如果单说基本块,那通过跳转语句和一些划分算法,可以想到把函数划分为一个一个的块,每个块里面存储着很多的语句,这每个块就是基本块呗,那 CFG 是用来干什么的呢?
CFG是程序中IR的逻辑关系的载体,后续自然也是为了优化(
因为优化其实是可以按照针对的部分,分成很多的种类的,比如说 基本块内优化,函数内优化,过程间优化 … CFG 就记录着基本块的前驱以及后继的种种关系,有助于你之后进行的各种优化,有了CFG记录的关系,你也可以建立新的关系,例如支配树(哭)。
要求
- phi函数是什么呢?对于分支形式代码如何转化为SSA形式呢?(答案竟然在题目中)
- 支配树是什么呢? 如何确立支配关系呢?(偏难)
- 去了解一些 Lengauer-Tarjan Dominators Algorithm 呢?借助网上各种资料
opt (优化)
小谢同学有了前面的铺垫,现在终于可以来到中端的优化环节了。
那优化到底是什么呢?
是有利可图的,逻辑不会变的同等状态的转移
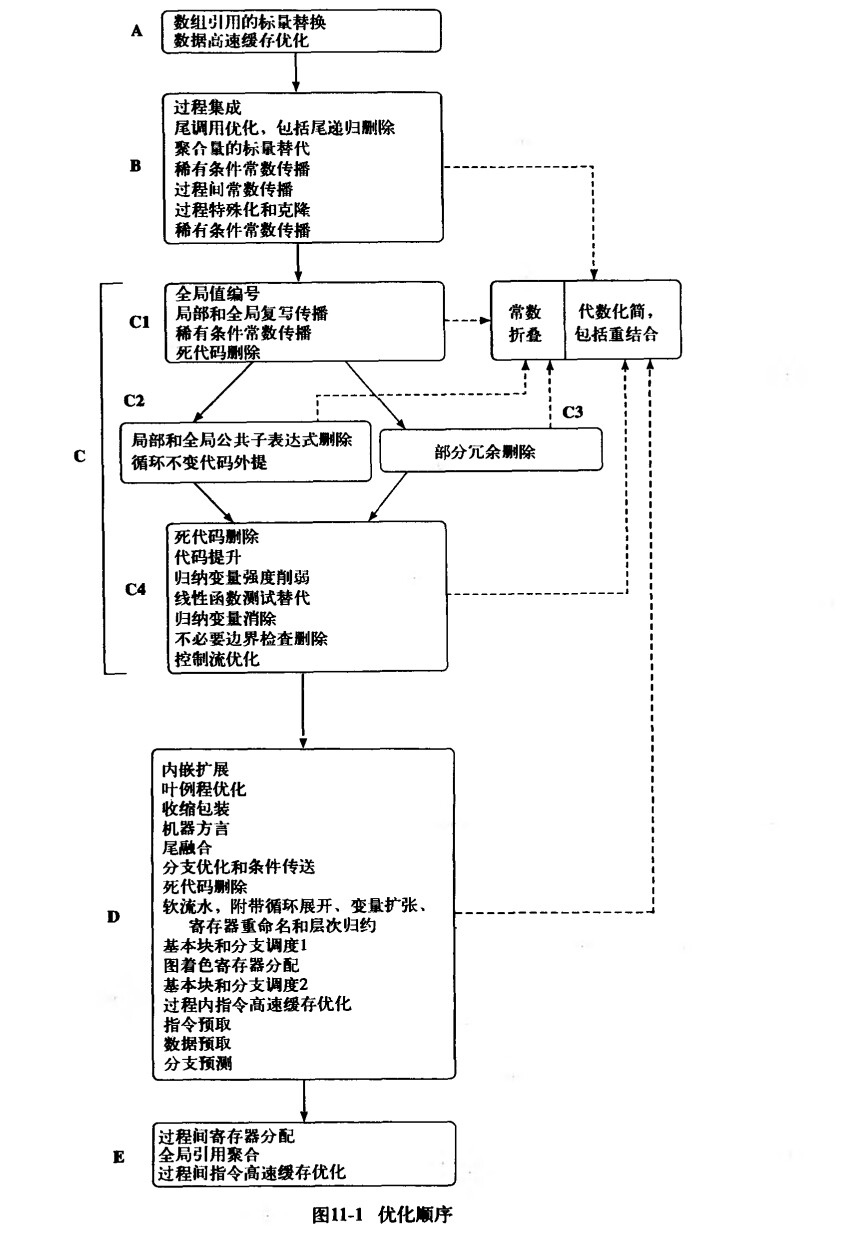
优化是一个专门的学问,在编译器的学习中,不同的优化可能有不同的侧重,但也可能会达到相同的效果,并且优化的不同顺序还会导致不同的结果,下图是鲸书中给出的一个优化顺序和一些优化,但针对不同的样例结构有些优化是很重要的,而另一些优化可能就不需要去执行,这些可能都需要我们去一点点实现。
GitHub - bigSheep123/JoTang_Compiler: To recruit new members for Caramel 这个小模型里面有我实现的几个优化,一般 mem2reg 是进入中端要做的 第一个优化,但是这个优化太难了,不会要求你在如此短的时间呢去实现,但是你需要去了解这个 优化,了解mem2reg的目的与作用。
小模型里面还有 DCE 和 sccp 优化的实现(也可以简单看一下),但是你的任务是根据提示(在 README.md 里面)去动手写一下 尾递归消除(Tail Recursion Elimination)的优化,详细的介绍和要求都写在了项目文档里面,这里不多介绍了。
要求
- 上网借助资料去了解 mem2reg,了解支配树与 mem2reg的关系
- 了解 phi函数与 mem2reg 之间的关系
- 调试起小模型的项目,并且完成 README.md 里面的需要完成
- 根据提示去完成 尾递归 调用优化,也可以按自己思路进行发挥 (难)
Task3
恭喜你了解了编译器前中端的部分,到现在开始和小谢同学一起进入编译器后端的学习。
在编译器的后端,我们需要针对目标机器的架构生成对应的汇编代码。(那么多种架构,我到底要做哪种???)在这节呢,我们需要针对RISC-V架构的目标机器来生成RISC-V汇编代码(RISC-V 是开源指令集)。可能读到这里你想到完成这道题目既需要完成编译器前中端,又需要从零开始写编译器后端,想想就头大!!!嘿嘿其实要小谢在这么短时间搓出一个完整的编译器前中后端也不是很现实的。本题只需要你完成很简单的任务,以此来了解一下RISC-V汇编即可。
题目内容:
- 配置环境:由于我们的笔记本电脑大多都是arm/x86环境,所以我们需要一个RISC-V,编译RISC-V完整工具链,并且配置qemu RISC-V环境模拟器。基于RISCV工具链和环境,你可以尝试整个从编译源文件到运行可执行文件的所有步骤,由于工具链不同,命令可能不同,在此只给出一个示范:
# 得到RISCV汇编文件
riscv-unknow-elf-gcc -S -o test.s test.c
#
riscv-unknow-elf-as -o test.o test.s
# 生成可执行文件
# “[ ]”中内容是可选项
riscv-unknow-elf-gcc -o test test.o [library.c] -lm
# 执行
qemu-riscv64 test [< test.in]
# 查看返回值
echo $?
- 了解RISC-V汇编语言程序,你需要关注的点包括但不限于:寄存器,堆,栈,指令。
- 根据给出的参考资料以及自己从网上搜寻的资料,使用RISC-V指令集实现选择排序程序,给出必要部分即可。
- (选做)尝试在qemu模拟器中调试你自己的riscv汇编
参考资料:
RISC-V汇编入门
riscv-gnu-toolchain
RISC-V Book
汇编代码调试
RISC-V Book 中文版
RISC-V GNU工具链的编译与安装
Task4
有了上面的对于RISC-V 程序的一个基本了解,让我们继续跟随小谢同学来开展编译器的后端,Task3 的部分是很重要的,如果你没有比较好的RISC-V 的基础,那么你肯定不能很好的想清楚之后的事情…如果觉得Task3 布置的任务完成的不好,请先完成Task3的任务,再进行下面内容的学习。
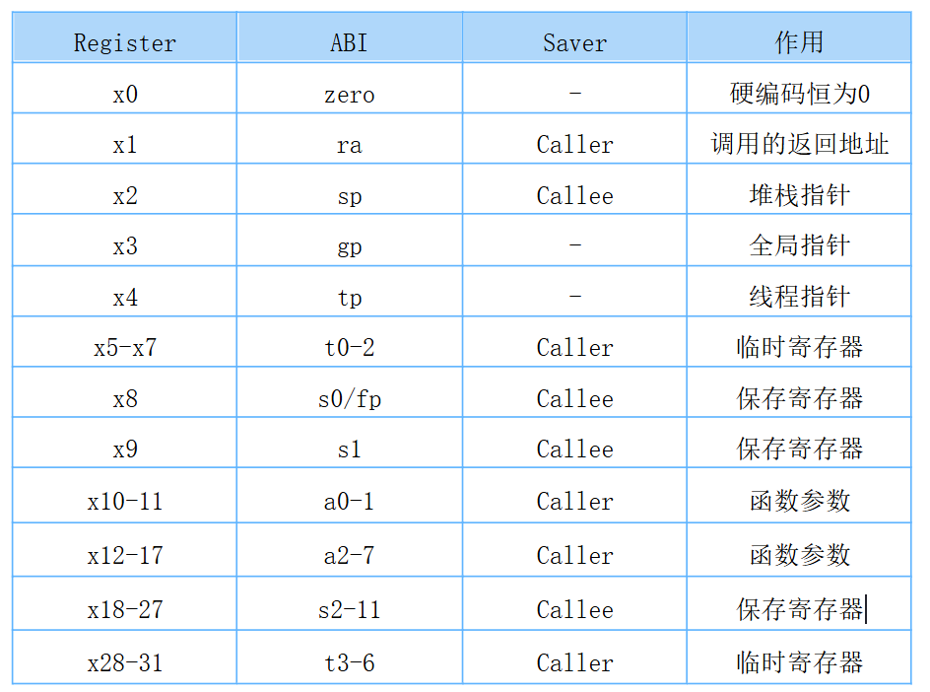
编译器的后端最简单的实现可以直接从IR 指令一条一条映射到RISC-V 指令,映射可能是一条对一条映射,也可能是一条对多条的映射,(当然这个代码量可能是庞大的),但是后端设计的难点在于你对栈帧的设计,以及寄存器的分配。如果你观察仔细,你会发现中端生成的 %.0, %.1,%.2其实你可以理解成虚拟寄存器,而且他们的个数是无限的,但是实际上寄存器是非常宝贵的资源,你在RISC-V 对应的寄存器是极其有限的(如下,这个仅仅是整数寄存器)。
如果你不分配寄存器,变量的值就存储在栈帧当中,那么你就必须使用 lw/sw 指令去在使用时加载变量/修改时存储变量到寄存器。但是如果随意使用寄存器,那么会导致寄存器中存储的值丢失,进而导致程序错误,并且有效合理的分配寄存器才能让生成的汇编代码是更加精简的。
(lw/sw 指令会使我们的指令周期大大增加,并且在RISC-V 架构下,我们无法直接使用内存中的值,必须要 load 到寄存器中才可以进行后续操作。)
在Task4 的任务下,你需要去搜集以及阅读相关文章,去了解更加详细寄存器分配的过程。
要求:
尽自己努力去了解就好,将自己了解到的和自己的思考记录下来。
小谢的编译器之旅也在这次的指导下有了进展与进步…
提交内容:
- 所有的程序源代码(需要上传到GitHub仓库,提交时提交链接)
- 你的Markdown文档,要把要求的内容写入Markdown中
考虑到我们的题目难度可能偏大,需要你去了解的东西很多很多,所以最终没有完全实现也是没有关系的,重要的是你这一路的学习理解过程,请务必记录在你的Markdown文档中!
如果有佬全部实现了所有的内容以及对计算机体系结构感兴趣,欢迎随时联系出题人:dh100086000 (wechat)