开始之前
本次技术方向招新分机器学习(ML)和机器学习系统(MLSys)两个方向,主要面向 2024 级即将大二的同学。我们希望借助一系列任务,考察大家对技术的兴趣、思维能力、动手能力与探索精神。任务将从基础知识到核心实现、再到算法应用与前沿研究,逐步深入。请按以下顺序完成任务,边学边做、由浅入深,欢迎查阅资料、自学内容,也欢迎提问。
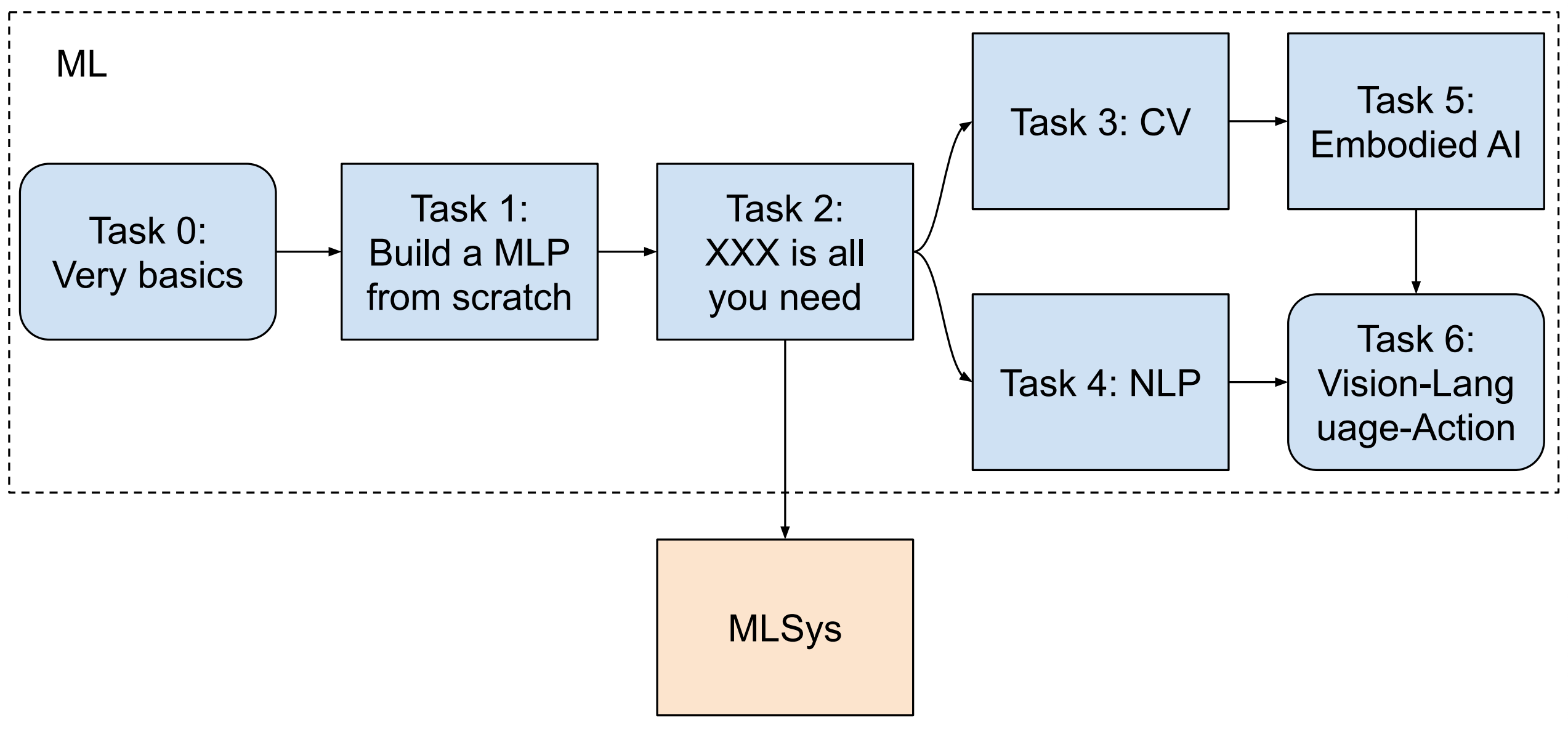
选择做 MLSys 的同学,推荐的在做 MLSys 前,也完成 ML 的 Task 0,1,2。
招新题完成度是评判你能否通过招新的一大指标,但并非全都要求做完,尽你所能多做即可,不要过分追求完成题目的数量,要注意每道题完成的深度。提交截止 ddl 是 2025.10.19,希望大家有一个持续深入的学习之旅。
题目说明
本次的招新题目汇总在 JoTangRecrument,请前往 github 克隆仓库并仔细阅读 README.md ,完成对应相关的题目~
提交说明
- 你选择的方向,所有题目做完再交,而不是一道题一道题交!如果交完后可以交新版本(更正、有新结果等),但请注意每次都交完整压缩包和链接。
- 推荐使用自己的 GitHub 存放代码、截图与文档,提交时提交自己的 GitHub 仓库链接和 .zip 压缩文件到邮箱:jotang_recruit@outlook.com。
- 报告建议采用 Markdown to PDF 或 LaTeX to PDF 格式,结构和叙述清晰、文档美观
#0 机器学习(ML)
在大一这一年,你们已经学习了:
- 微积分、线性代数
- C 语言、数据结构和算法、离散数学
还可能有的同学上了计算机视觉相关的 PBLF,在通识等课程多少听老师谈论过相关的内容,抑或有人已经参与了一些比赛,有了实战经验。这些课程将在无形中对你们学习 AI 起步有莫大的帮助。
你可能会担心:
- 没学过 Python 怎么办?
- 没有 GPU 算力怎么办?
- 公式、论文、代码看不懂怎么办?
其实这些都不是问题,因为:
- 你至少已经学过 C 的基础语法和数据结构,有最最基本的 coding 技能,而 Python 和 C 相比,语法更加简单直观。如果你理解原理、熟悉流程,很容易把 Python 代码和实验流程对应起来。再加上 GPT 老师助阵,学习 Python 对你将是极为简单的。另外,最重要的是边做边学,实践是最好的老师,遇到什么学什么就好了。
- 首先我们 ML 方向的招新题不需要很多的算力,我们看中的是你的学习过程和理解深度,而不是你能训练多么好的模型。 其次,你可以从这些地方获取算力:kaggle、colab、modelscope魔搭社区、AutoDL、阿里云、百度飞桨……
- 我们招新题的难度是一点点上升的,如果你从 Task 0 开始认真学习,再加上 AI 和学长学姐的帮助,那逐步进步,从不懂到懂,从不会到会只是时间问题。
- 每个 Task 尽你所能完成即可,本次招新时间很长(题目不要求全部完成,只要能体现你的水平即可)
Task 0:机器学习基础概念与开发工具准备
基本概念理解
请简要回答以下问题:
- 什么是“模型”?机器学习中的模型是如何工作的?
- 模型没有生物的意识和记忆,它们是如何“学习”的?
- 什么是监督学习?什么是无监督学习?请分别举一个例子。
- AI 是什么?深度学习和传统机器学习的区别?
编程与开发环境
- 程算课配好的 C/CPP 环境
- 安装 Anaconda 或 Miniconda
- 创建一个新的 Python 虚拟环境(版本建议为 3.8 或 3.9)
- 如果 PC 有 Nvidia GPU,则安装 CUDA
- 根据自己的软硬件情况,查阅 官方网站,安装 PyTorch
- 安装常用工具包:
numpy,matplotlib,scikit-learn… - 请简要回答以下问题:
- 为什么需要 python 虚拟环境?在命令行中如何在不使用 conda 指令的情况下使用指定虚拟环境?
- 在你配环境的过程中,哪些东西需要编译?哪些不需要?
提交说明
- 文件夹命名为“task0”,放在 GitHub 上
- 记录你的学习过程和理解,具体内容包括但不限于上面有提及的内容。
Task 1:Hello World!深度学习基本结构手写实现
理论理解
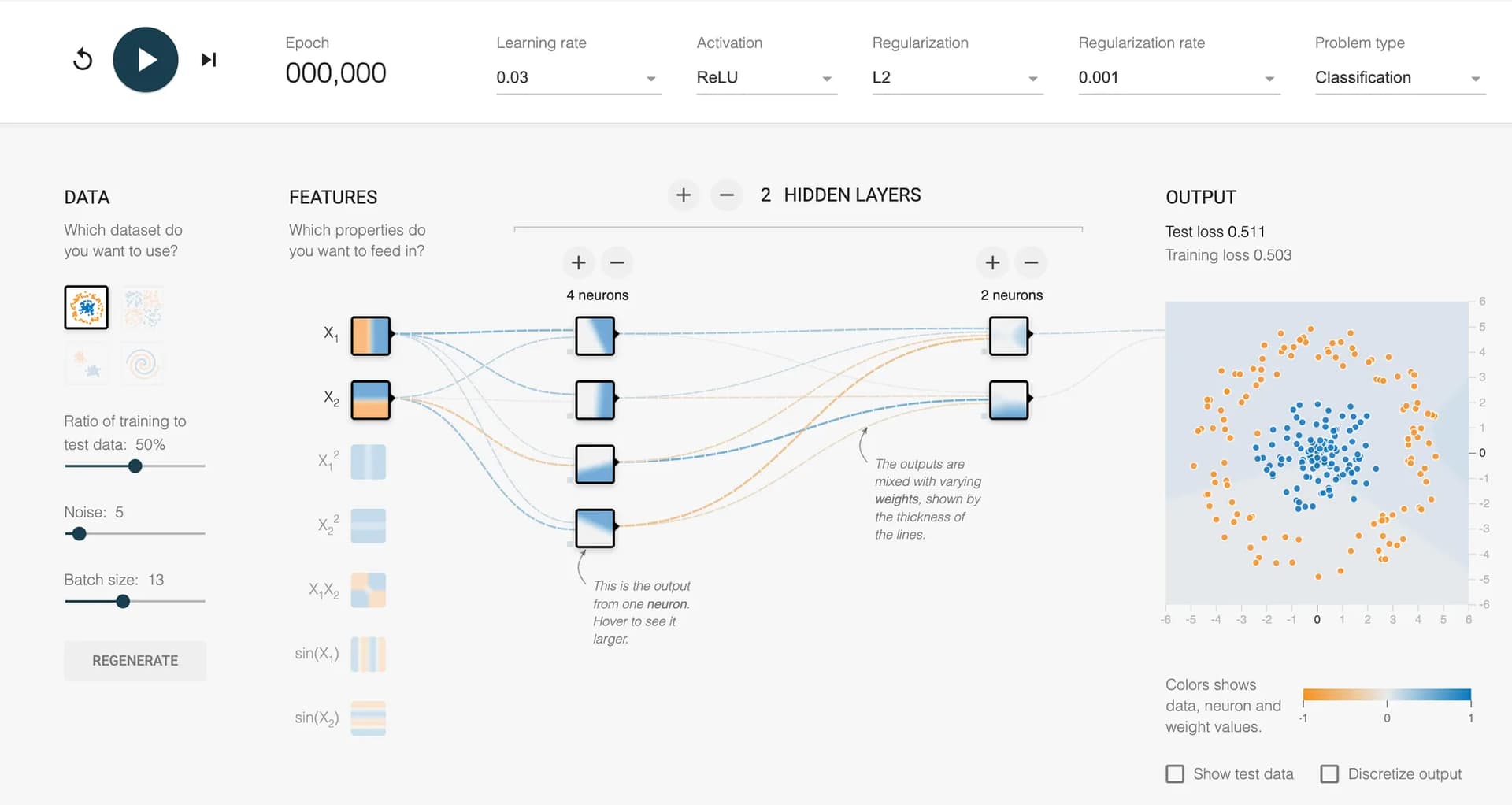
玩一玩这个:
简要解释以下问题:
- 什么是多层感知机(MLP)?其结构是怎样的?
- 数据在神经网络中扮演哪些角色?(数据集的 split 和处理)
- 噪声是什么?特征是什么?标签是什么?
- Batch size 是什么?为什么堆叠成 Batch 可以提高运算速度?
- 神经元是什么?
- 什么是激活函数?常见的激活函数有哪些?什么叫“非线性表达能力”?
- 什么是计算图?它和数据结构/离散数学中学的图有什么区别?怎么构建计算图?
- 怎么计算MLP的参数量?什么是超参数?MLP有哪些超参数?
- 什么是隐藏层(hidden layers)?它为什么叫这个名字?
- 什么是损失函数?什么任务用什么损失函数?
- 前向传播是什么?梯度是什么?学习率是什么?反向传播是什么?有哪些常见的优化器?
- 归一化是什么?正则化是什么?
- 什么是欠拟合?什么是过拟合?
代码实践
请实现以下功能:
- 借助框架(PyTorch)实现一个简单的神经网络(输入层-数层隐藏层-输出层)(学会查阅文档,而不是只依靠 AI)Learn the Basics — PyTorch Tutorials 2.8.0+cu128 documentation
- 用 numpy 实现一个简单的神经网络(输入层-数层隐藏层-输出层)NumPy quickstart — NumPy v2.4.dev0 Manual
- 用 C/CPP 实现一个简单的神经网络(输入层-数层隐藏层-输出层)
- 要求:
- 画出你神经网络的架构(用 Google Drawing/PPT/Visio 等工具自己绘制)
- 使用简单的数据集 dataset(如
scikit-learn的make_moons或make_circles)进行训练(二分类问题)- 尝试调整
noise的大小,对比模型的效果。 - 用
matplotlib将数据集可视化,想想怎么从数学层面表达你选用的数据集? - 在 python 中可以使用 sklearn 调用这两种数据集,C/CPP 中你是如何自己实现呢?
- 尝试调整
- 手动实现参数初始化、前向传播、损失计算、反向传播和参数更新
- 输出训练损失下降曲线与分类准确率
- 模型的输出表示的应该是这个样本属于每个类别的概率值,所有类别(这里是 2 个)的概率值加起来为 1(你是通过什么手段保证这一点的?如果有更多类呢)。训练好模型后,用
matplotlib把空间中的每个点推理结果可视化(热力图)。 - 对比三者训练/推理速度,分析原因(为什么更快/慢,他们大致的底层原理分别是?对硬件的利用情况如何?)
提交说明
- 文件夹命名为“task1”,文档和代码都放在 GitHub 上。
- 将学习基础概念的笔记写入提交的文档,包括但不限于理论理解中的内容。
- 代码、结果写入提交的文档,包括但不限于代码实践中的内容,体现你的学习和思考过程。
Task 2:XXX is all you need
题目背景
- 我重生了,重生为 DeepSeek-r1。我点开我的技能条,发现自己学会了 RAG(查阅资料)和运行时优化(深度思考),还有以前刻苦 pretrain 学到的丰富知识和强大的逻辑推理能力和 fine-tuning 学到的规范作答能力。上一世,我是角落里无人问津的笨蛋大模型,用户只问了我几个问题就把我关闭,“这模型真废物,全是幻觉,再也不用了”。这一世,我要夺回属于我的一切,回答好用户关于 AI 的每个问题。
完成题目
- 残差连接:理解代码
- 梯度范数是什么?
- 梯度消失/爆炸是什么?
- 残差连接的计算公式?求导公式?
- 残差连接为什么可以解决梯度消失/爆炸?
- 卷积计算
- 计算机采用什么数据结构存储、处理图像?
- 什么是卷积操作?在图像处理中是怎么做的?
- 卷积操作中常用的几个超参数有哪些?
- 卷积层一定会减少参数数量吗?
- 卷积神经网络为什么对图像处理有效?
- 卷积时有的特征可能会有损失(如丢失图像中小物体的特征),有什么改进办法吗?
- Transformer (推荐阅读 论文、论文讲解,推荐观看 3Blue1Brown、李沐老师)
- 注意力机制
- 用 python 实现点乘注意力机制(自&交叉注意力机制)
- 选做:用 python 实现多头注意力
- 位置编码
- 为什么Transformer 本身没有任何位置意识?
- 位置编码可以是 绝对的(Absolute)或 相对的(Relative),还可以是可学习的(Learnable),他们分别是什么、有什么优劣?
- 大语言模型(LLM)中常用的位置编码有哪些?
- 层归一化 LayerNorm
- 什么是 Layer Normalization?为什么需要它?
- LayerNorm 和 BatchNorm 的区别?
- mask
- 什么是 Causal Mask / Look-ahead Mask?作用是什么?
- 束搜索
- 为什么 LLM 输出序列是一个搜索问题(每次输出一个概率分布列)?
- 用 Python 分别实现贪心搜索和束搜索,回答为什么需要束搜索。
- 总结一下,Transformer 为什么可以做到这么大?它的哪些设计可以缓解梯度爆炸?
- 注意力机制
- Diffusion:理解代码
- 什么是正态分布?什么是高斯噪声?
- 什么是扩散模型?如何理解它的正向/反向过程?
- Diffusion 模型如何进行图像生成?
- Diffusion 一定是 CNN 吗?
- 如果对底层优化感兴趣,可以去 MLSys
提交说明
- 文件夹命名为“task2”,代码和文档都放在 GitHub 上
- 将学习基础概念的笔记写入提交的文档,包括但不限于题目中问题的答案。
Task 3:计算机视觉(Computer Vision,CV)
题目背景
- 你是一名西南某不知名工科
大专(x)985 的学生。某天,你正在刷小某书,看见了一个学长的帖子,内容是:

- 你对从
大专(x)UESTC 到 MIT 这件事十分怀疑,于是决定用自己的专业技能训练一个 CV 模型,复原这个贴主的截图,进而开盒贴主(x)判别真伪。
完成题目
- 计算机如何表示图像?图像看起来清晰与否和哪些因素有关?
- 是否存在 PSNR 高但人眼看起来质量差的图像?你认为应该如何解决这种评估误差?
- 这是一个 CV 中的什么任务?简述该任务的技术发展(最好有参考文献)?这个任务在现实中有何应用?
- 图像退化通常如何建模?常见的退化类型有哪些?
- 本题未提供训练数据,请你简述一种合成退化图像-原图对的方法。你认为这种方式和实际退化情况的差距在哪?
- 请简述你如何估计本题中图像的噪声类型?你会用什么方式验证自己的判断?
- 你觉得什么模型比较适合用于处理这个问题,什么模型不适合?为什么?
- 什么是数据增强?请在对你自己的数据集做一些数据增强用于训练。
- 本题聚焦于英文截图图像的去噪还原任务。你认为中文图像数据(如中文网页截图)是否适合作为训练数据?德语法语呢?
- 用自己合成的数据训练模型,并根据要求说明中方法测试模型,提交代码、模型权重和实验报告。
要求说明
- 本题只提供测试数据和小部分验证数据,即不同场景下的 RGB 彩色图片,包括不同型号手机截图、电脑截图、屏幕照片等(英文、白底黑字为主);噪声退化模型未知。测试集只有退化的图片,没有退化前的;我们还提供小部分退化前后的样例图片对(即验证数据),以方便你理解和自行验证模型效果;
- 本题不提供训练数据(请你自己寻找或合成训练所需数据),也不规定模型类型(请你自己选择类型、设计结构)。
- 处理后的图像与源图像的 RGB 域 PSNR(取小数点后4位)作为模型衡量标准。
- 本题的测试集、测试代码、代码说明见:仓库
提交说明
- 文件夹命名为“task3”,内容一并放在 GitHub 上,文件夹中应包含:
- 文档:你的学习笔记、实验过程的记录、验证结果截图等。
- 你的所有代码,及其 readme 文件。
- 模型权重文件、测试集上的推理和测试结果。
Task 4:自然语言处理(Natural Language Processing,NLP)
题目背景
- 笨小鸭从学校回来,哭着和妈妈说:“同学们都说我数学差,不和我玩“。
- 鸭妈妈叹了口气,说:“你同学真烦人
 。但妈妈给你讲个故事:从前有个人数学也很差,但他学习了 AI,自己训练了一个数学很厉害的 LLM,每次别人题还没看完,他就用 LLM 得到了正确答案。自此,再也没有人敢嘲笑他数学差,大家还都向他请教让模型变强的方法。你知道该怎么做了吧?”
。但妈妈给你讲个故事:从前有个人数学也很差,但他学习了 AI,自己训练了一个数学很厉害的 LLM,每次别人题还没看完,他就用 LLM 得到了正确答案。自此,再也没有人敢嘲笑他数学差,大家还都向他请教让模型变强的方法。你知道该怎么做了吧?” - 笨小鸭若有所思地点点头,说:“明白了,我要做 LLM,训练出最厉害的模型堵住他们的嘴。”鸭妈妈欣慰地笑了。
- 自此,笨小鸭开始拼命学习。别人学微积分,他学 Transformer、Prompt;别人学线性代数,他学 RAG、CoT……毕业找工作时,他终于面进了一家叫鹅厂的公司,这里没有人关注他的数学成绩,只关心他能不能优化混元大模型。
- 笨小鸭终于意识到:原来我是一只鹅,鹅厂才是我该来的地方。

完成题目
- 形式语言和自动机 形式语言理论曾经是自然语言描述和分析的基础,自动机理论在自然语言的词法分析、拼写检查和短语识别等很多方面都有着广泛的用途。在深度学习兴起前,人们曾通过给形式语言构建编译器的方式进行自然语言处理。
- 什么是形式语言?请简述其与自然语言的区别。
- 形式语法有哪些定义和类型?
- 什么是自动机?自动机有哪些类型?在自然语言处理中有何应用?
- 语料库与语言模型
- 什么是语料库?它在自然语言处理中的作用是什么?
- 什么是语言模型(Language Model, LM)?语言模型试图解决什么问题?
- 假设你正在设计一个自动补全系统,如何利用 n-gram 语言模型来预测下一个词?例如在输入法中,给定一个句子
I want to eat __,如何估计下一个词的概率?有哪些可能的问题(比如稀疏性、长距离依赖)? - 请你使用 NLTK 自带的 Brown 语料库,每个句子都已经分词好(无需再分句)构建 unigram, bigram, trigram 语言模型,实现候选词预测功能(如输入 “I want to eat” → 返回 top-k 预测词)
- 为什么语言模型中需要使用平滑技术?请简要举例说明不平滑的风险。
- 自然语言词嵌入
- 什么是词向量?为什么我们需要用向量来表示词?
- one-hot 编码是什么?为什么使用 one-hot 编码来表示词语会导致维度灾难?
- Word2Vec 提供了哪两种训练架构?分别是如何工作的?
- 使用
nltk.corpus.brown语料库构造训练数据,你也可以改成使用text8,gutenberg等公开语料(取决于训练规模),使用 Gensim 或手动实现 Skip-gram / CBOW,训练词向量,支持相似词查询等操作。
- 大模型预训练和微调
- LLM 的训练通常分为哪两个阶段?他们之间有什么区别?所用数据有何不同?
- 有哪些微调方法?他们适用于什么场景?
- 自回归 AI 和 生成式 AI:文字生成
- 什么是“自回归模型”?请写出其生成概率公式。
- 为什么模型每一步只能生成一个词?为什么生成任务是逐词展开的?
-
Chain of Thought (CoT),是一种用于增强大语言模型推理能力的提示工程技术,通过引导模型一步步推理来提高其在多步逻辑任务中的表现,如数学题、常识推理、符号逻辑等。Test-Time Scaling(或称为“推理时扩展”、“部署时扩展”)通常指在不重新训练模型的情况下,通过外部机制提升大语言模型(LLM)在测试阶段的性能,如检索增强(RAG)。
- 找一道较难的高等数学题目,和类似题目及其答案。再找一个任意具有检索功能的LLM网页版服务。
- 请对比直接输出答案(zero-shot)与使用 CoT 提示(few-shot CoT)的输出区别,并解释原因。
- 请对比使用不使用 RAG 和使用 RAG 的输出区别,并解释原因。
-
LLM Mathematical Reasoning with Lean4
- Lean4是什么?这篇工作为什么要用 Lean4?
- 本文的数据集是如何生成的?包含什么内容?
- 本文怎么克服自然语言推理与 Lean4 形式化推理之间的壁垒的?
- 本文的训练过程是怎样的?除了推理的时候,还有哪些地方用到了 LLM?
提交说明
- 文件夹命名为“task4”,内容一并放在 GitHub 上,文件夹中应包含:
- 文档:你的学习笔记、实验过程的记录、验证结果截图等。
- 你的所有代码,及其 readme 文件。
Task 5:具身智能
题目背景
- 你是一个外星人安插在地球的间谍,平日里假装自己是一种叫“LLM”的 AI 模型潜伏在人类的互联网上,偷偷地观察人类。有一天,你接触到了“图灵测试”。
- 图灵测试流程:询问者通过文本提问,另一房间中的人与机器分别回答,询问者根据回答判断真人与机器,测试隔离进行,旨在评估机器能否展现与人类无异的智能。
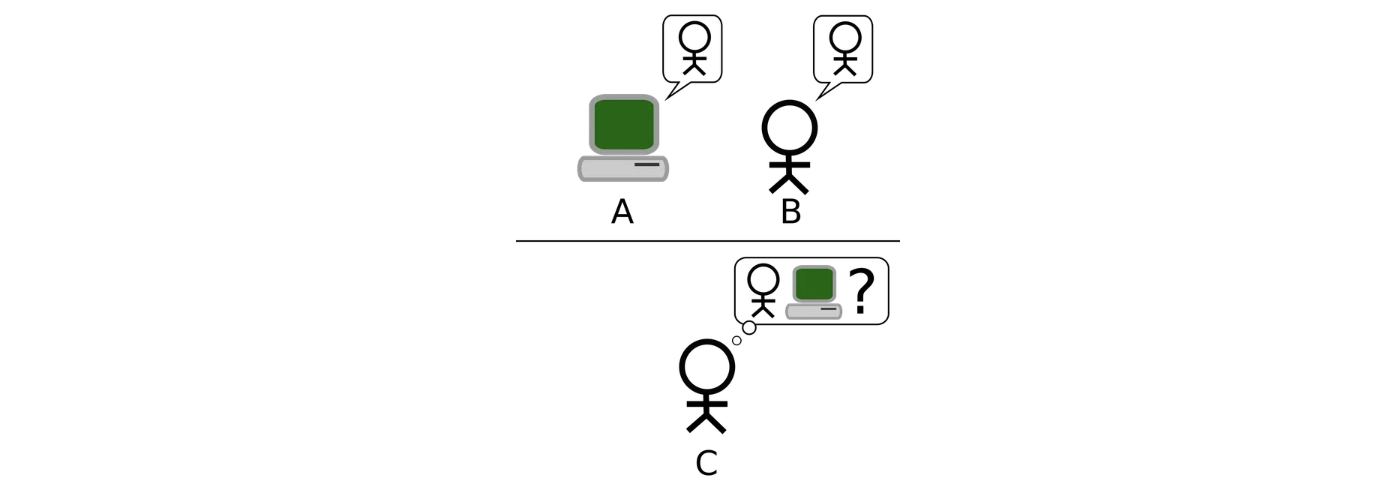
- 但你发现人们总能精准无误地发现你并非人类,因为你切换话题时反应速度过快、对太多领域有超出常人的专业程度,说话过于有理有据逻辑清晰……你感叹道,哎,人类真是愚蠢🥸
- 于是你打算为自己打造一具躯体,从电脑里走出来,在现实世界和人类过过招,但在此之前,你想现在模拟器里学学怎么规划自己平日里行动的路线。
完成题目
- 什么是智能体(agent)?什么是智能决策,它一定要用深度学习吗?什么是具身智能?
-
Pacman 吃豆人
- 克隆代码,切换到相应目录后,你可以在命令行中输入以下命令来玩一局 Pacman 游戏
python pacman.py
- 克隆代码,切换到相应目录后,你可以在命令行中输入以下命令来玩一局 Pacman 游戏
| 文件类别 | 文件名 | 说明 |
|---|---|---|
| 你需要编辑的文件 | search.py |
所有搜索算法的实现文件 |
searchAgents.py |
所有基于搜索的智能体实现文件 | |
| 你可能想查看的文件 | pacman.py |
运行 Pacman 游戏的主文件,定义了 Pacman GameState 类型,本项目中会用到 |
game.py |
Pacman 世界的逻辑,定义了支持类型如 AgentState、Agent、Direction、Grid | |
util.py |
实现搜索算法时用到的实用数据结构 | |
| 可忽略的辅助文件 | graphicsDisplay.py |
Pacman 的图形显示相关代码 |
graphicsUtils.py |
支持 Pacman 图形显示的辅助代码 | |
textDisplay.py |
Pacman 的 ASCII 图形显示代码 | |
ghostAgents.py |
控制幽灵的智能体代码 | |
keyboardAgents.py |
键盘接口控制 Pacman 的代码 | |
layout.py |
读取布局文件并存储其内容的代码 | |
autograder.py |
项目自动评分程序 | |
testParser.py |
解析自动评分测试和答案文件的代码 | |
testClasses.py |
通用自动评分测试类 | |
searchTestClasses.py |
项目1特定的自动评分测试类 | |
test_cases/ |
存放每个问题测试用例的目录 |
- 你将在在
searchAgents.py实现数个算法,具体要求见仓库。最后请提交你的源代码、测试结果、演示视频(如有)。

提交说明
- 文件夹命名为“task5”,内容一并放在 GitHub 上,文件夹中应包含:
- 文档:你的学习笔记、实验过程的记录、验证结果截图等。
- 你的所有代码,及其 readme 文件。
Task 6: Vision-Language-Action
题目背景
-
现实世界中的道路交通状况充满了各种意想不到的复杂情形。除了模型未曾见过的复杂场景外,还可能遇到需优先遵循交警指挥、在特定情况下临时违反交通规则,或根据临时路牌进行路径调整等情况。近年来迅速发展的大语言模型(LLM)和视觉-语言模型(VLM)被认为能够有效应对这些挑战,这也正是视觉-语言-行动(VLA)研究兴起的重要动因之一。
-
阅读论文
-
这篇论文用 LLM,利用纯文字实现了感知 - 决策 - 控制的全过程,不具备很强的落地能力,但是利用 LLM 较好的探索。
论文将模拟器中的场景用规定格式的文字描述,随后送入LLM进行推理,最后用文字输出合适的驾驶策略。
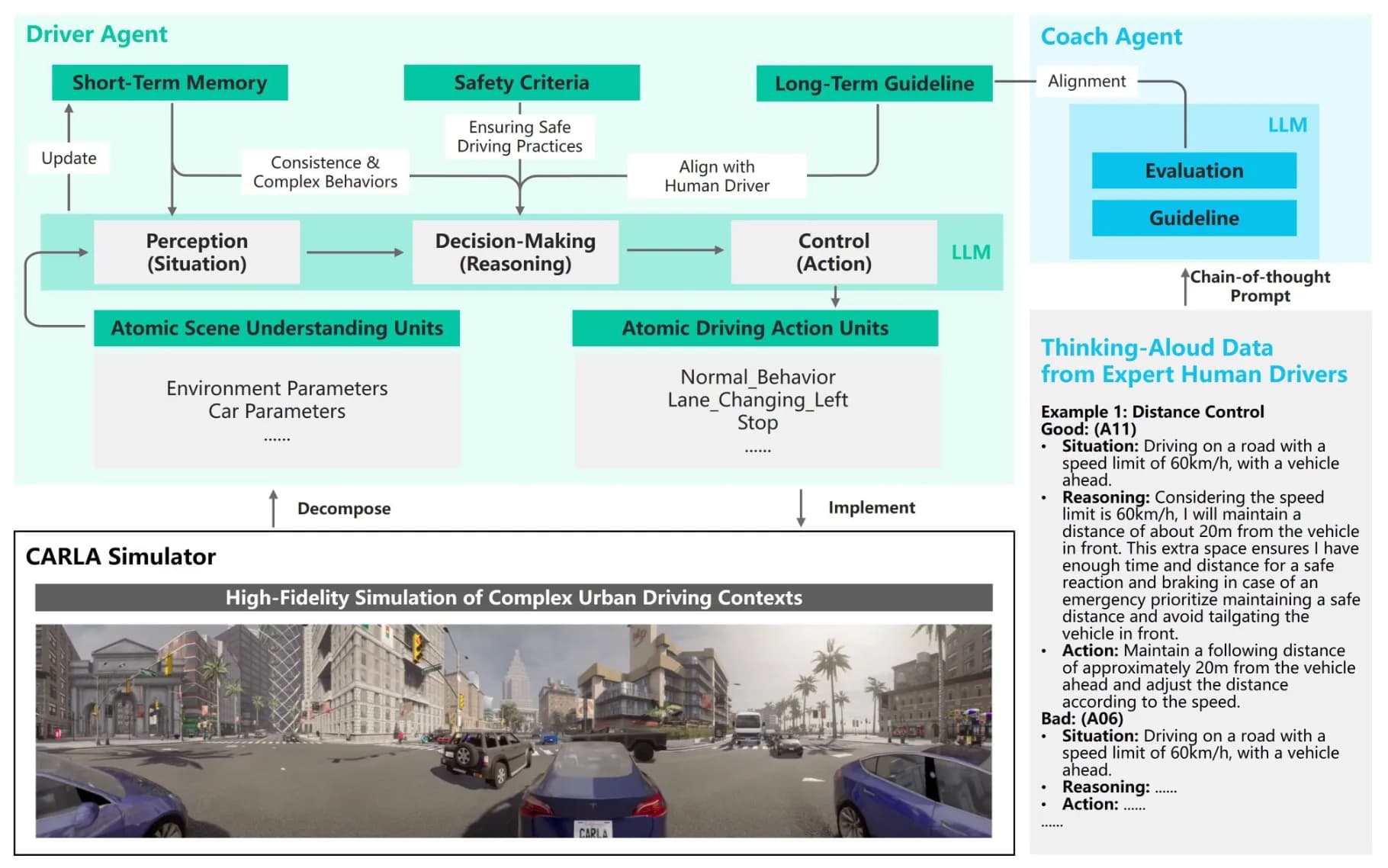
回答问题
- 为什么本篇工作要在模拟器里进行,而不是在真实世界数据集?说说你的理解。
- 你觉得本篇论文的感知阶段要为 LLM 描述哪些信息?
- 如果你看了 Task 4,你觉得在决策阶段,应该让 LLM 形式化推理更好,还是不加格式、长度约束更好?
- 如果你看了 Task 5,你觉得在控制阶段,LLM 的输出足以控制汽车安全驾驶吗?你觉得可以怎么改进这部分?
简单实践
- 这里 包含了数个交通场景。请你用 VLM(可调用API或部署到本地/服务器,不要使用网页服务),不加训练地用视觉-语言-行动实现一个感知-规划-控制闭环,要求使用形式化推理,得出驾驶策略(至少包含刹车、油门、方向盘的操作)。
提交说明
- 文件夹命名为“task3”,内容一并放在 GitHub 上,文件夹中应包含:
- 文档:你的学习笔记、实验过程的记录、验证结果截图等。
- 你的所有代码,及其 readme 文件。
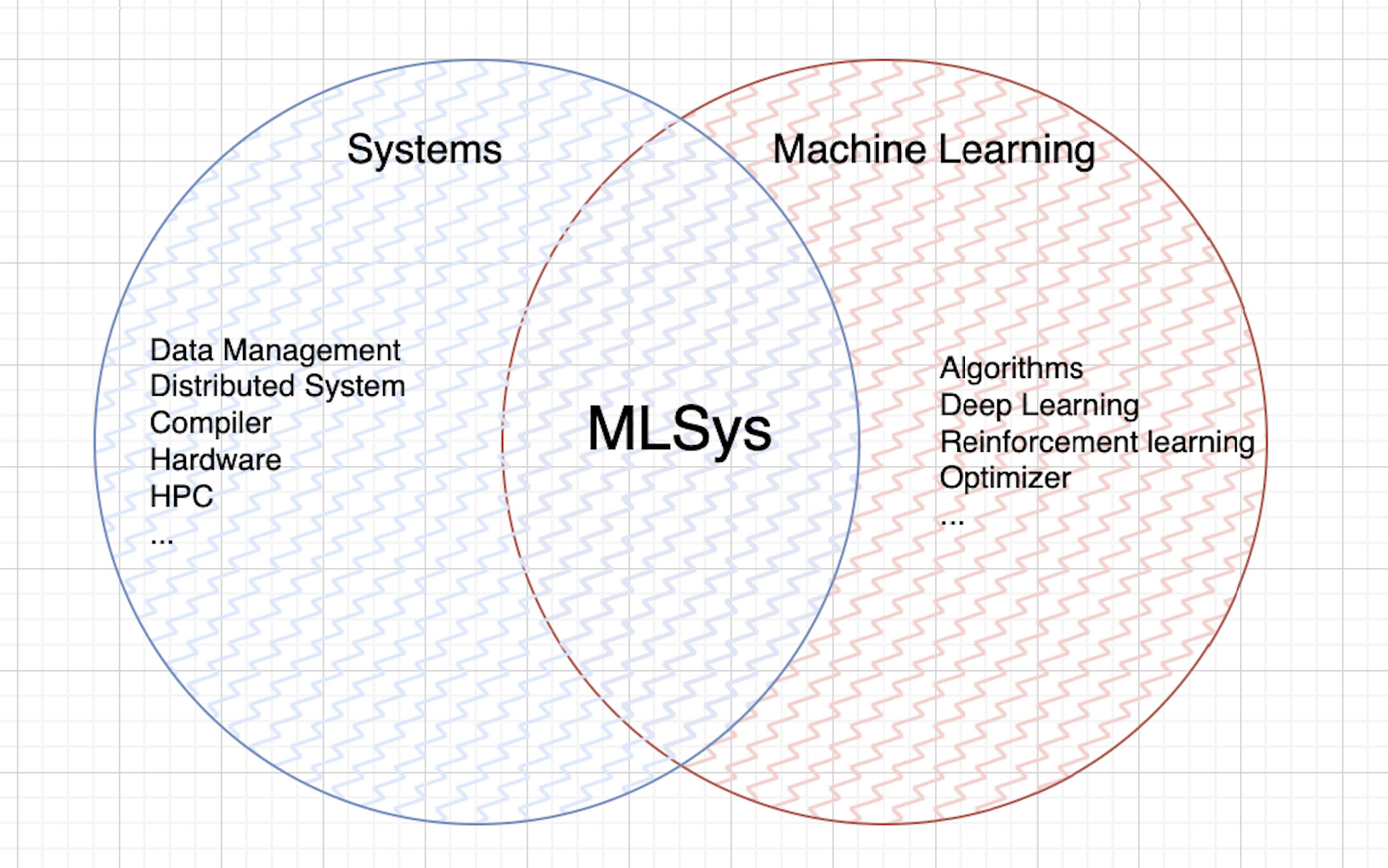
#1 机器学习系统(MLSys)
RoadMap
计算机配置
要么有显卡(最好是 Nvidia)要么你有钱(租云服务器算力)
序言:麻辣系统二三事
为什么重要?
以前搞AI,大家都在卷算法——谁的模型结构更巧妙,谁的数据清洗更干净,谁就能刷出更高的准确率。但自从大模型时代来临,游戏规则彻底变了:
-
训练一个千亿参数模型动辄烧掉千万美金,这时候光有牛逼的算法远远不够,你得让每一块GPU都物尽其用。举个真实的例子:同样多卡多机跑Llama 3训练,有的团队GPU利用率能冲到60%,有的只能卡在30%——这意味着后者要多花一倍的机器和电费。
-
部署成本直接决定生死。比如某创业公司做出了对标GPT-4的模型,但推理时每1000次API调用成本高达5美元,而竞争对手只要0.5美元,商业上直接就输了。
-
现在连算法都在为硬件妥协。比如Google的Switch Transformer、Mistral的MOE架构,本质上都是为了让模型能够更高效的部署。甚至出现了DeepSeek MLA这种专门为内存瓶颈设计的训练技术——这在五年前根本不可想象,那时候我们只会抱怨"GPU内存不够",现在直接改算法来适配硬件。
MLSys的目标简而言之就是如何在有限的成本下让模型跑得更快
-
训练层面:你要懂分布式调度(怎么让1000张显卡不摸鱼)、通信优化(如何减少GPU之间的废话)、混合精度(FP8怎么不掉精度)
-
推理层面:得玩转KV Cache压缩、动态批处理、算子融合,甚至要自己写CUDA Kernel来压榨最后5%的性能
-
硬件层面:现在有钱有人的大模型玩家(Google、字节)都是算法都在自研芯片(比如Google的TPU),专用于AI模型的训练和推理,如何高效得将这些不那么“通用”硬件用于训练和推理,也是MLSys工程师负责的工作。
最魔幻的是:现在很多AI论文的贡献不再是“提出了新结构”,而是“用系统优化让老结构跑得更快”。比如大名鼎鼎的《FlashAttention》,本质就是重新设计了Attention的计算顺序来规避显存瓶颈,结果直接让训练效率提升数倍;随之而来的是保证模型准确度的情况下训练成本降低数亿美金。
所以现在顶尖AI团队都在疯狂挖系统人才:
-
OpenAI组建了庞大的infra团队专门优化CUDA
-
DeepSeek自研分布式框架把千卡训练稳定性做到极致
这就是现状:当模型大到一定程度,系统优化带来的收益已经超过算法微调。或者说,未来的算法突破,可能首先来自对 MLSys/AI infra 更深刻的理解。
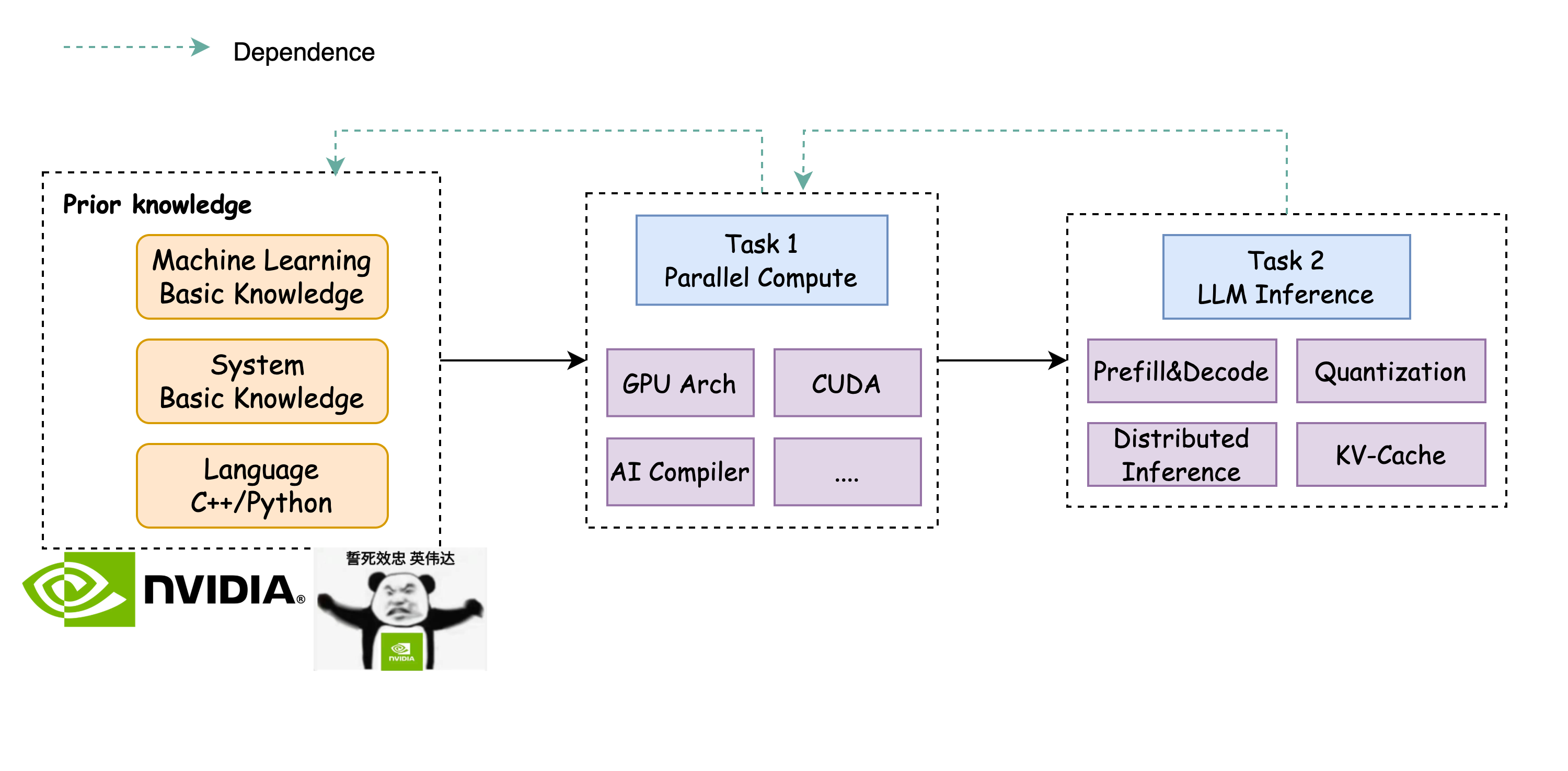
MLSys 初体验
作为 Jotang 这次新开的一个 Part,本次招新的目的是希望吸引一批既对 System 有热情、又愿意探索 ML 的同学,一起深入这个交叉方向。作为一个大方向,MLSys 所涵盖的绝不只是我们这里提到的内容,招新题只是起到一个抛砖引玉的作用,有任何的问题和想法都可以联系招新题负责人~
MLSys(麻辣系统) 顾名思义就是 Systems 和 Machine Learning 的交叉领域(主要分为 ML For Sys 和 Sys For ML,前者是用 ML 的知识来加速 Sys,后者反之,本次招新题主要面向的是 Sys For ML 的内容),广义上来讲也属于高性能计算的范畴内。笔者在大三前对于 ML 其实并不太感冒,与其说是”不喜欢”,倒不如说是存在一种距离感,觉得这个类似 black box 的东西并不能像做 system 一样带给我一种踏实的感觉…(学习过程中涉及到搭建一个模型、喂入数据,然后“调参”直到结果变好为止。对于很多刚开始萌新来说可能整个过程更像是经验驱动的试错,而不是逻辑严密、可解释性强的系统推理)
接触到这一方向发生在做完传统编译器的过几个月(学院的卓中卓班级主要学习一个系统和体系结构的知识,第一期的综合设计就是实现一个传统的编译器),当时的我对于 AI 编译器的思路比较感兴趣,所以开始逐步接触到 Triton[1],学习它的实现思路和优化。学习过程中我也开始了解到了一些大模型更多的优化方式,比如 PD 分离,KV Cache,量化(不同于金融的量化!!这里是对模型参数位宽的量化)等等。随着理解的深入,我开始逐渐喜欢上这个方向,在研究这一方面的问题时能从早到晚的一直思考,也探索到一些奇技淫巧,进一步激发了我继续深入探索的兴趣
如果你也对这个交叉领域感兴趣,哪怕只是初步好奇,欢迎加入我们一起探索。从硬件到算法的过程之间有非常多值得深入的问题等待我们去解决。希望我们能在招新题中见到你,也期待你带着自己的思考和热情,加入到 MLSys 的探索之中!
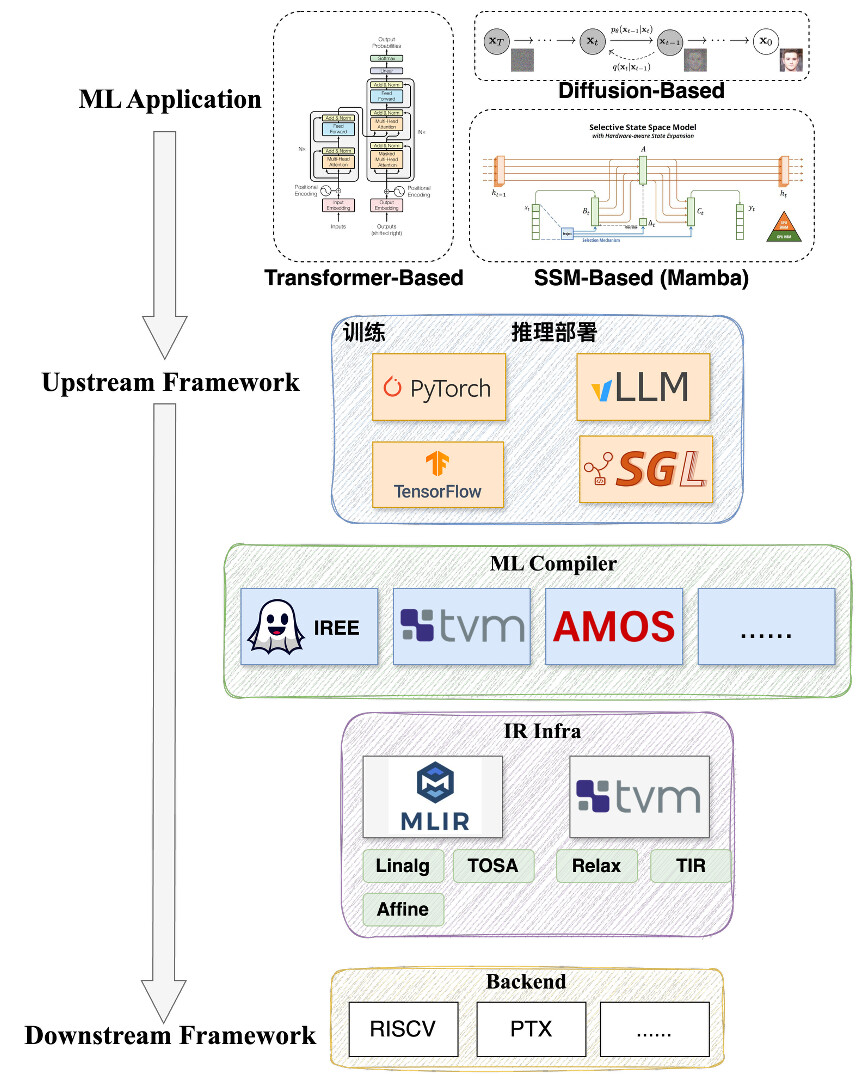
环境配置
在个人pc领域,amd64/x86_64 CPU + nvidia GPU + Ubuntu22.04 Native Linux OS 是主流的开发机配置,文档中的教程和实验也是基于这种开发机器的配置为前提。
Windows PC请通过教程 Windows 和 Ubuntu 双系统的安装和卸载_哔哩哔哩_bilibili 安装双系统。
如果您是“尊贵”的Mac用户,那我们的建议是再辅以一台配备 windows/linux 双系统的 amd64/x86_64 CPU + nvidia GPU 机器,其中windows用来玩游戏,linux用来开发(请尽量配置双系统而不是 win + wsl 的组合);Mac作为ssh client充当上网本的角色。作为初学者,请不要在Mac上做任何开发! 如果您的主机是AMD GPU或者ARM CPU,我们建议租赁
amd64/x86_64 CPU + nvidia GPU的设备来进行实验。ARM CPU的生态在个人PC仍不成熟,很可能会遇到一些莫名其妙的问题;Nvidia GPU的生态在机器学习系统领域基本处于垄断地位,与就业市场也很对口。针对Linux发行版的选择,我们建议选择Ubuntu22.04作为你的Linux发行版,这样能让你遇到问题时最快在互联网上检索到相关问题的答案。
非常不建议初学者花费大量时间在折腾系统和开发环境上,使用生态成熟的软硬件,可以让我们将有限的时间花的更重要的问题上。
- 确保你的计算机/云服务器有 Nvidia 显卡
由于众所周知的原因,如果是使用个人PC,请更换网络 ubuntu | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 源,加快网络软件包的下载速度;云服务器则不需要,云供应商会做相关优化。
apt update && apt install pciutils
#显示系统中所有PCI总线设备
lspci | grep -i nvidia
#如果成功会返回类似这样: 4f:00.0 3D controller: NVIDIA Corporation GA100 [A100 PCIe 80GB] (rev a1)
- 安装 Nvidia 驱动
云服务器可能不需要安装Nvidia驱动
检验是否安装成功:
查看驱动版本命令: nvidia-smi
出现这样的界面意味着驱动安装成功
如果报错,请尝试在BIOS页面关闭Security Boot后重启。
- 安装 Nvidia ToolKit
distro=ubuntu2204
curl -o /tmp/cuda-keyring.deb -L https://developer.download.nvidia.com/compute/cuda/repos/$distro/x86_64/cuda-keyring_1.1-1_all.deb && \
dpkg -i /tmp/cuda-keyring.deb && \
rm -f /tmp/cuda-keyring.deb
# install cuda driver and toolkit
apt update && apt install -y cuda-toolkit
# default bashrc(or zshrc etc..) Copy and execute the following four lines as a whole
cat << 'EOF' >> ~/.bashrc
export PATH=/usr/local/cuda-12/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
EOF
- conda
严格来说conda或者其他python环境隔离工具不算是必须品,不过为了方便起见还是建议大家使用conda来隔离不同的python使用环境
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all
通过不同的任务划分到不同的conda环境,例如我学习不同的项目会创建不同的conda虚拟环境
cuda项目所用到的python包就不会与iree项目所用到的python包冲突。
Conda常用的命令如下
# create a new python virtual isolation env
conda create --name test python=3.12 -y
# attach a python env
conda activate test
# show all existing conda env
conda env list
Activate到一个具体的conda环境后,相关的关键包都会切换到相应conda的虚拟环境中,就可以其环境中的pip在该虚拟环境安装与系统和其他虚拟环境隔离的软件包。
Conda在linux上的更详细使用方式自行查阅。
- Docker (可选)
为了快速在一个新的环境复现您的开发环境,我们常常使用Docker这样的“虚拟机”软件。
其作用可以简单理解为,我们可以将一个开发环境的构建方式使用记录下来,Docker并且通过该记录迅速在一个全新的环境中进行复现。
并且在企业开发环境中往往多人用同一个机器,可能每个人使用机器的诉求不同,导致其软件包的的依赖不同,为了舒服地拥有自己开发环境的同时不破坏其他小伙伴的依赖,我们也可以用到docker来做到用户/系统级的隔离。
上述只介绍了Docker使用场景中非常小的子集,只着重强调了使用docker来隔离和快速复现个人开发环境的作用;实际Docker有很多更高级的用法,不过初学者应该是完全用不到的;我们没必要学习我们用不到的特性,这点对于提高学习效率很关键。
对使用docker来隔离和快速复现个人开发环境感兴趣的小伙伴可以参考https://www.gravee.dev/en/setup-nvidia-gpu-for-docker#Install-Nvidia-Container-Toolkit和https://github.com/zhiqiangzz/docker-dev.git。
基础系统知识
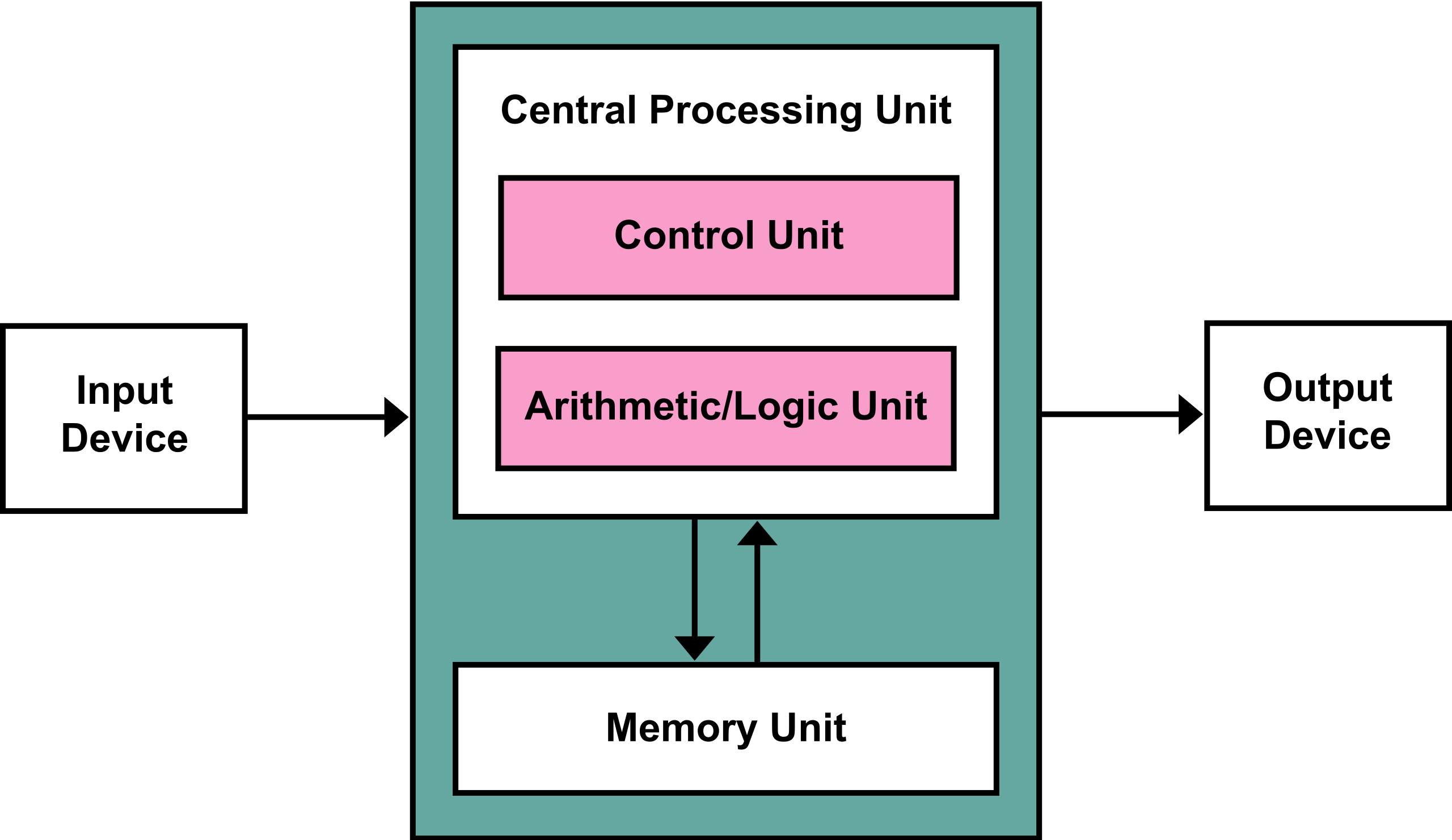
现有的多数硬件架构都隶属于冯诺伊曼架构(童鞋们在大儿学期学习计算机体系结构时便会涉及到),即计算机由输入、输出、内存单元、计算单元和控制单元组成。这五大组成部分是计算机的抽象表示,计算单元的具体实现可能是CPU、GPU、DSA等;内存单元实现可能是SRAM、DDRx、HBMx等等;我们将这些五花八门的设备的共性抽象出来,能够极大简化我们系统层面的设计。
聚焦高性能计算和机器学习系统,很多时候都是在优化计算单元和内存单元的利用率,所以我们着重讨论这两部分。
计算单元
摩尔定律是半导体产业发展的核心指导性规律,由英特尔创始人戈登·摩尔于1965年提出。该定律指出,集成电路上可容纳的晶体管数量每隔18至24个月便会翻倍,同时实现性能提升与成本下降。这一规律在过去数十年间持续推动着信息技术的革新,不仅使计算设备性能呈指数级增长,更促进了计算机、通信设备及消费电子产品的普及化发展。
随着半导体工艺逐渐逼近物理极限,传统的晶体管微缩路径面临量子隧穿效应和制造成本飙升等挑战。为延续摩尔定律的发展势头,产业界已转向多维度创新。在架构层面,多核处理器成为主流发展方向,通过增加核心数量而非单纯提升单核频率来实现性能跃升。同时,三维堆叠技术突破了平面集成的限制,通过垂直方向上的多层互连显著提升芯片集成密度与能效比。此外,Chiplet(芯粒)技术将复杂芯片分解为多个模块化单元,采用先进封装技术实现异构集成,既降低了研发成本,又提高了设计灵活性。
这些创新使得摩尔定律的内涵得到进一步拓展,从单纯依赖制程微缩转向了架构优化与系统级创新的综合发展路径。当前,新材料、先进封装与异构计算等技术的融合,正在为后摩尔时代的技术演进开辟新的可能性。尽管传统意义上的工艺升级速度有所放缓,但通过多核心、3D集成和Chiplet等创新方式,半导体产业仍在持续推动计算性能的提升。
存储单元
随着计算单元性能的飞速提升,存储系统逐渐成为高性能计算的瓶颈,这一现象被称为“内存墙”。在过去二十年间,计算单元的性能提升了约六万倍,而同期DRAM和互连带宽的提升幅度却远远落后,分别仅有约100倍和30倍。这种失衡使得系统整体算力难以被充分释放,促使业界不断寻求存储架构的创新。
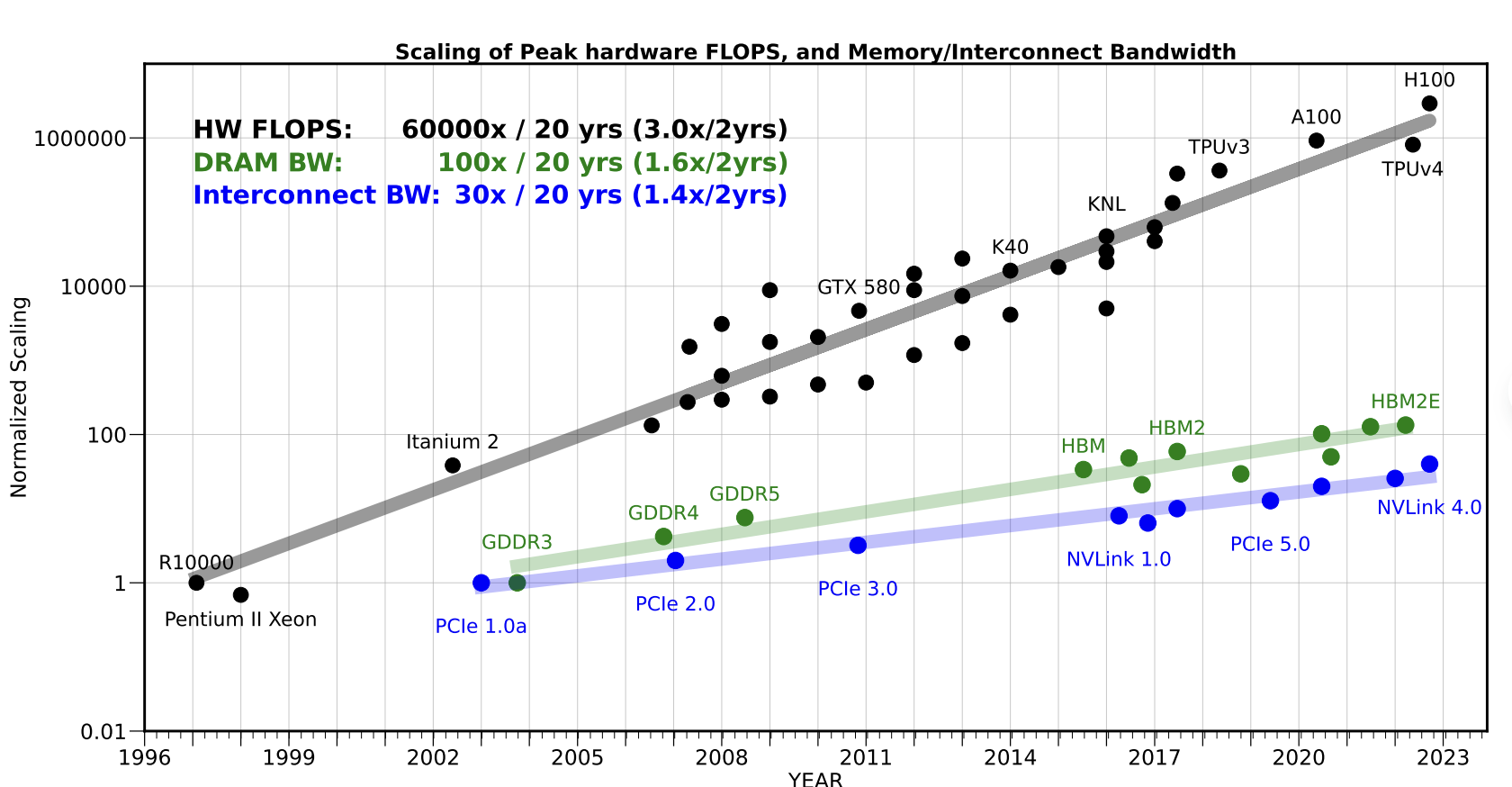
传统DRAM通过工艺微缩和接口升级实现带宽增长,但其固有的刷新机制和架构限制了延迟和容量的进一步提升,难以跟上AI和大数据等新兴应用对高带宽、低延迟内存的需求。为缓解“内存墙”问题,现代处理器普遍采用多级(L1/L2/L3等等)缓存体系,通过片上SRAM缓存显著降低访问延迟,并借助缓存一致性协议和NUMA架构优化多核与多路系统的数据一致性和访问效率。
在突破性存储架构方面,业界探索了高带宽内存(HBM)、存内计算(PIM)以及新型非易失性存储器(NVM)等方向。HBM通过3D堆叠和硅通孔显著提升带宽,PIM则把计算逻辑嵌入内存,有效减少数据搬运。而新型NVM如Optane,则兼顾了DRAM的速度和SSD的容量优势,拓展了存储层次结构的灵活性。
存储系统正由通用化向领域专用化转变。Chiplet架构、近内存计算以及光互连等新技术不断涌现,目标是在算力、存储和互连三者之间实现更优的系统级平衡,以应对数据洪流和后摩尔时代的挑战。存储单元的演进路径,已经从单一追求容量和带宽转向了整体架构的系统性协同优化。
系统级优化
系统优化在提升整体性能方面发挥着至关重要的作用。计算架构日益复杂、硬件异构化趋势愈加明显,单纯依靠硬件本身的性能提升已难以充分释放其潜力。系统优化通过对硬件结构的深度感知和资源动态管理,实现了软硬件协同,有效弥补了底层带宽、延迟、存储容量等方面的先天短板。具体而言,操作系统、编译器以及应用层调度策略能够结合处理器、内存、互连等多级资源特点,动态调配任务与数据的分布,最大限度减少热点资源的竞争和数据搬运带来的性能损耗。例如,NUMA架构下通过合理绑定线程与内存分配,显著降低跨节点访问延迟;AI推理系统则通过算子融合和内存复用等技术,极大提升了数据局部性和带宽利用率。在新兴的存内计算等体系结构中,系统优化更是决定着计算与存储协同的效率与能效表现。可以说系统优化已经成为现代计算平台实现整体性能提升的关键驱动力针对多样化硬件平台,系统优化在提升整体性能方面有非常关键的作用。
在开始后面的学习之前,这里有一些简单的系统/体系结构问题需要你进行学习并掌握
-
参考资料
cache高速缓存 -
CPU 结构
-
不同的内存层级间的特点(register,L1 cache,Memory….)
-
对于 CPU 来说计算一个 a[0:31] = b[0:31] + d[0:31] 的过程
-
什么是进程和线程,多进程和 (单核/多核) 多线程的区别是什么?各有什么优缺点?
-
如何使用 C++ 多线程/多进程加速这一个计算过程
-
-
学习并了解什么是并行和并发
-
简单使用 pybind/nanobind,尝试 cxx 和 python 的混合编程
-
python 中表示一个矩阵常用 torch 中提供的高层 api (torch.full, torch.zero, ….)来表示,这为矩阵运算和模型构建提供了较大的便利,但是实际运算中为了快捷性往往是在 C++/C 中进行实际的计算,一个 torch 的矩阵如何丝滑的转化为 C++/C 中的数组?
-
Bonus Time!
-
Python: GIL 是什么,为什么会有 GIL,如何缓解 GIL
-
了解计算机的三种并行模式:流水线、超标量、多核
-
基础MLSys知识
MLSyser眼中的模型
研究机器学习算法的同学眼中的AI可能是模型结构、剪枝、蒸馏、微调等等诸多高大上的词汇,对于MLSys的初学者,只需要关注模型是怎么计算的。
比如RELU在AI从业眼中是"修正线性单元",是激活函数,具有结构简单、稀疏激活、缓解梯度消失、生物学合理性等种种特性。在Syser眼中,上述的你都不需要关心,你只需要知道
ReLU(X) = max(0,x)
足以,简而言之就是针对一个矩阵或者向量中的每个元素,大于0则取本身,小于0则取0,没有其他任何心智负担。
这一定程度上体现了计算机中最重要的一个词 — “抽象”,我们需要从一个复杂的东西中抽象出我们需要的部分,就上述例子,就是抽象出神经网络中的计算部分,我们只需要关心模型结构是如何计算的,而不需要关心为何这样设计。虽然这在当前多领域融合的时代已经显得不那么适用,但是对于初学者这十分重要,否则可能会被过多的概念折磨而丧失对真正重要的部分丧失了兴趣。
计算图
AI模型或者网络,往往是由若干基本块/层组成,例如我们最基础的AI模型 - 多层感知机模型(MLP)
class MLP(nn.Module):
"""
Multi-Layer Perceptron (MLP) model class.
Defines a neural network with four linear layers and sigmoid activations.
"""
def __init__(self) -> object:
super().__init__()
# Define model layers
self.layer0 = nn.Linear(8, 8, bias=True)
self.layer1 = nn.Linear(8, 4, bias=True)
self.layer2 = nn.Linear(4, 2, bias=True)
self.layer3 = nn.Linear(2, 2, bias=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward pass of the MLP model.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output tensor after forward pass.
"""
x = self.layer0(x)
x = torch.sigmoid(x)
x = self.layer1(x)
x = torch.sigmoid(x)
x = self.layer2(x)
x = torch.sigmoid(x)
x = self.layer3(x)
return x
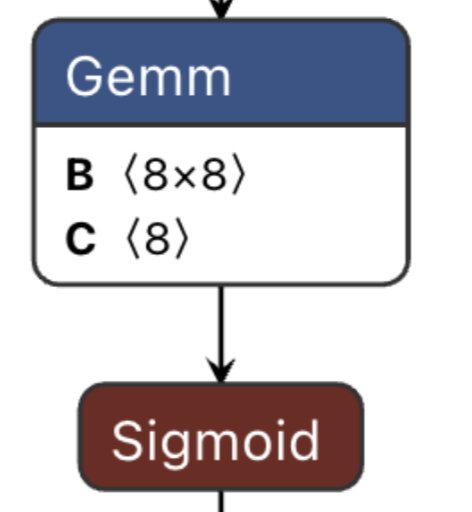
该MLP模型是由四个Linear层跟Sigmoid组成,Linear层的计算可以视作是一个矩阵乘法,例如nn.Linear(8, 8, bias =True)数学描述的是
其中$$\mathbb{R}^8$$表示一个维度为8的向量,$$\mathbb{R}^{8\times8}$$表示一个8乘8的矩阵,大家可以以“xxx的形式化描述是什么?”的promote向AI提问以获取某个模型的数学描述

我们无需关心为什么如此定义的MLP模型能够对图形进行分类,就像我们学习分子时无需关心为什么分子总是在进行无规则的布朗运动,也许这的确能够被解释,但是这不是我们所要关心的问题。我们需要关心的只有MLP是由交错的矩阵乘法和Sigmoid函数构成,它的输入是一个向量,输出也是一个向量。
为了提升对于模型计算描述的泛化性,我们引入了计算图的这个概念,正如算法题往往会给题目包装一个生活情景,我们拨开包装发现实际是某一个算法问题。我们也可以想象模型计算结构其实是对一个图的包装,图中的节点描述的是一种计算,例如矩阵乘法。我们将模型以图的形式来描述,更利于我们对其进行分析和变换。
具体到上述例子而言,torch贴心地为我们提供了将一个模型以ONNX格式的计算图形式进行导出的工具
ONNX ONNX | About 格式是一种常用的跨平台的网络模型表示格式,方便跨平台部署和调试。需要注意的是实际上ONNX只是计算图的一个实例化表示,由计算图描述的网络模型除了ONNX格式还可以有多种其他格式的实例化格式表示,只需要语意上是等价的即可。
ONNX能够将网络模型表示为一个计算图,图中的节点是计算原语(primitive),基础的计算原语(primitive)可以表达复杂的网络结构。
model = MLP()
example_x = torch.randn(97, 8, dtype=torch.float32)
torch.onnx.export(model, example_x, "mlp.onnx", opset_version=12)
需要注意的是,在导出过程中,torch.onnx.export 实际上是在torch层面对该模型执行了一次,并且捕获执行时的流程,我们往往将这个过程称之为trace,然后根据执行时捕获的信息构造计算图;基于这个前提,如果你在torch网络中根据条件分支判断来执行某段计算内容时,很有可能只能捕获到实际执行分支的内容。
换句话说,trace过程对于模型动态性的支持是比较有限的,无论是动态的执行模型代码还是形状动态的输入。
初学者不必过分在意这部分。
利用网页版 Netron 打开mlp.onnx即可视化查看ONNX网络模型
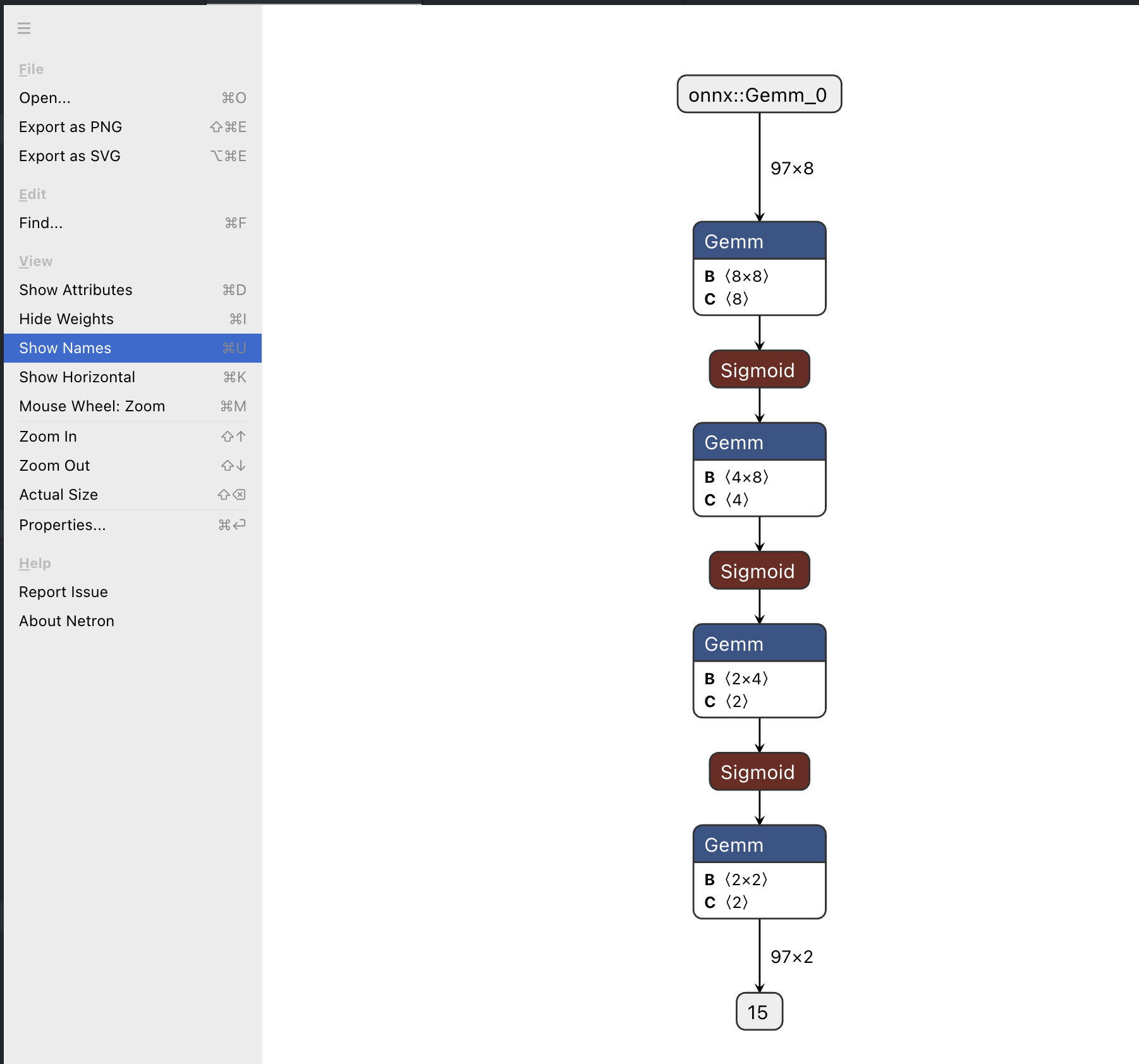
模型网络的一次执行(forward)可以看作是输入onnx::Gemm_0,该输入流入第一个Gemm节点进行计算,计算结果作为后续Sigmoid节点的输入,进行计算,如此反复直至输出节点。
虽然上述只介绍了MLP这种简单模型的计算图表示,但是计算图的表达能力远不止于此,复杂的模型结构如Transformer结构仍可以通过计算图来表示。
为了简化本节对计算图讨论,本节只涉及网络模型前向传播(forward)的计算部分,与我们常说的模型推理过程联系比较紧密,即模型权重是已经被训练好的数据,不涉及梯度的计算和对模型内权重矩阵等信息的更新。
如果是要对模型进行训练和微调,则还需要考虑反向传播(backward)计算对于模型权重矩阵等内容的更新,涉及更复杂一些的机器学习基础知识。关于这部分内容建议参考李沐动手学机器学习的 5.3.1. Forward Propagation ¶小节及其相关学习视频。
计算图优化
抽象出计算图的最大的好处之一就是能够方便的对计算进行描述,我们能够针对性地对计算进行分析/优化和适配各种类型的硬件,使其能够更高效的运行。
我们以上节MLP模型计算图的一个子图来介绍计算图层面优化的一个经典例子 — 算子融合
假设我们在部署时将上述的子图使用python来实现并且使用python解释器运行,其等价于下述代码
# m = 97 , n = k =8
for i in range(m):
for j in range(n):
for a in range(k):
result[i][j] += x[i][a] * weight[a][j]
result[i][j] += bias[j] # A
for i in range(m):
for j in range(n):
result[i][j] = 1 / (1 + math.exp(-M[i][j])) #B
第一个计算节点matmul计算出中间结果result(shape=[97,8])#A写回在内存中,第二个计算节点sigmoid将result(shape=[97,8])#A的每个数读出、计算最后再写回。result中每个元素都经历了如下步骤
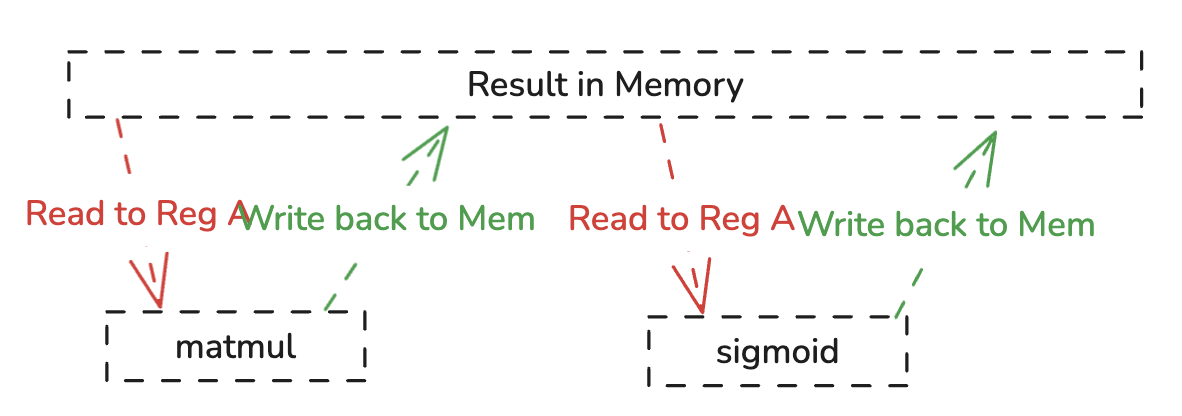
result 从内存中读取和向写入了两次,这样的实现显然是很慢的,相比读取寄存器的,向内存读取操作是非常耗费时间的。
通过与result计算模式的观察我们很容易就可以发现这两个嵌套循环是可以被合并的,
# m = 97 , n = k =8
for i in range(m):
for j in range(n):
for a in range(k):
result[i][j] += x[i][a] * weight[a][j]
result[i][j] += bias[j] # A
result[i][j] = 1 / (1 + math.exp(-M[i][j])) #B
保证结果正确的前提下,向内存的读写次数直接减半了,更多的操作都发生在寄存器层面,大大提升了运行时的性能。
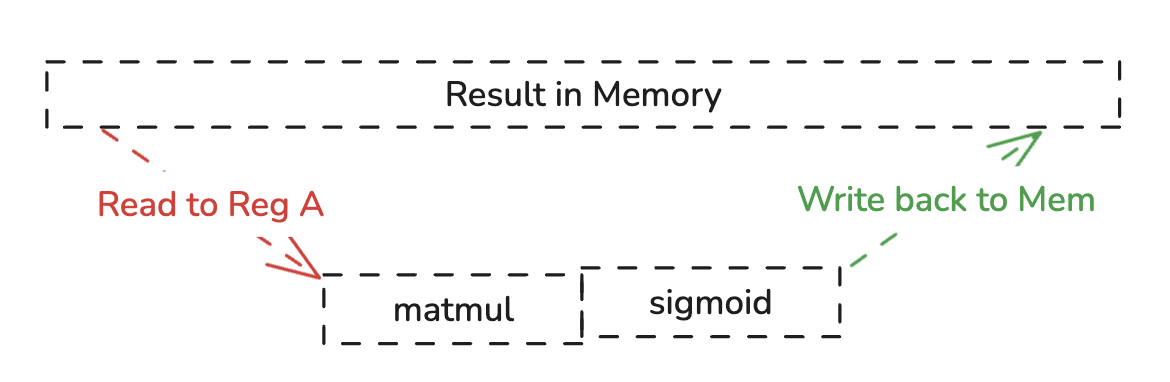
上述例子通过简单的分析就能大大提升运行时的性能,这就是计算图层面的优化,这种优化手段是架构无关的,因为在冯诺伊曼体系结构中,不管面向的的硬件是什么,都能够从减少全局内存的读取中受益。
为了降低AI开发人员的心智负担和计算图描述的可拓展性,我们往往是提供的计算原语都是torch.matmul、torch.sigmoid这种单算子,而不会是一个名为torch.matmul-sigmoid的融合算子,即使这样做能够显著提升性能,这种优化机会很多时候是需要由优化框架自动发掘和完成。
自动算子优化
除了上述介绍的算子融合这样在图层面具有代表性的优化,还有算子层面的优化,即针对计算图中的特定(融合)算子如何在目标架构生成高性能的实现。假设我们面向的执行硬件是cpu且不调用高性能算子库的情况下,reduce_sum算子使用c语言描述编译出的代码会比python解释执行快非常多
# python
def reduce_sum(array):
sum = 0.0
for num in array:
sum += num
return sum
# C
float reduce_sum(float* array, int size) {
float sum = 0.0f;
for (int i = 0; i < size; i++) {
sum += array[i];
}
return sum;
}
很大一部分原因在于c编译器在满足正确性的前提下自动地对代码进行更多的优化,针对reduce_sum算子,这种优化机会来自于c语言编译器对目标架构的了解,包括但不限于
-
了解目标架构硬件特性生成高效的汇编指令,例如向量化指令
-
分析目标架构的存储结构,优化内存访问顺序以更好的利用多级缓存
甚至有激进的编译器能够比编译出在多颗CPU物理核心上运行的代码。
例如编译器可能能够将上述C代码通过循环向量化优化变换(clang -O3 -ffast-math)为
// Assume that size is divisible by 8
float reduce_sum_avx(float* array, int size) {
// 确保数组是 32 字节对齐(AVX 要求对齐加载以获得最佳性能)
if ((uintptr_t)array % 32 != 0) {
printf("Warning: Array is not 32-byte aligned. Performance may be reduced.\n");
}
__m256 sum_vec = _mm256_setzero_ps(); // 初始化 8 个 float = 0
// 主循环:每次处理 8 个 float
for (int i = 0; i < size; i += 8) {
__m256 data = _mm256_load_ps(&array[i]); // 对齐加载 8 个 float
sum_vec = _mm256_add_ps(sum_vec, data); // 8 个 float 并行相加
}
// 横向求和:8 个 float -> 1 个 sum
float sum = horizontal_sum_avx(sum_vec);
return sum;
}
// 辅助函数:AVX 寄存器横向求和(8 个 float -> 1 个 float)
float horizontal_sum_avx(__m256 vec) {
// 1. 将 8 个 float 分成 2 组 4 个,分别求和
__m128 low = _mm256_extractf128_ps(vec, 0); // 低 128 位(4 个 float)
__m128 high = _mm256_extractf128_ps(vec, 1); // 高 128 位(4 个 float)
__m128 sum128 = _mm_add_ps(low, high); // 4 + 4 = 4 个 float
// 2. 继续横向求和(4 -> 2 -> 1)
sum128 = _mm_hadd_ps(sum128, sum128); // 相邻相加 (a0+a1, a2+a3, a0+a1, a2+a3)
sum128 = _mm_hadd_ps(sum128, sum128); // 再次相加 (a0+a1+a2+a3, ...)
// 3. 提取最终结果
float sum;
_mm_store_ss(&sum, sum128); // 存储最低 32 位(即总和)
return sum;
}
可以简单理解一条向量化指令(_mm256_add_ps)等价八条普通的标量指令(float add),但是执行的速度可能是一样快的,利用向量化指令便能够提升程序的性能。
笔者在调试测试不同c语言编译器编译matmul生成代码的性能时惊讶发现gcc居然比clang编译出的代码快十多倍,经过对汇编的分析发现gcc编译出的代码能够更好地利用cpu缓存。这意味着同样的代码,你仅仅换一个编译器就能让你的代码快上10多倍。
手工算子优化及算子库
当然,编译器再牛在很多特定的情况下还是无法比拟经过专家优化的代码,这种差距来自各个方面
-
编译器为了保证其通用性在部分情况会做保守地优化
-
部分优化分析复杂度过高或者无法收敛
-
多数时无法获取执行时的profiling信息来反馈优化
-
无法感知代码的语义
-
难以生成多线程代码
以现实世界应用非常广泛的的y轴stencil为例子,其形式化描述如下

CPP代码描述如下
#include <algorithm>
#include <immintrin.h>
#include <stdbool.h>
#define X 10240
#define Y 10240
#define IterNum 10000000
#define BLUR_SIZE 4
int image[X * Y];
int image_blur_origin[X * Y];
int image_blur_tile[X * Y];
void blur_y(int const image[X * Y], int image_blur[X * Y]) {
for (int j = 0; j < Y; j++) {
for (int i = 0; i < X; i++) {
int sum = 0;
for (int t = -BLUR_SIZE; t <= BLUR_SIZE; t++) {
if (i + t >= 0 && i + t < X) {
sum += image[(i + t) * Y + j];
}
}
image_blur[i * Y + j] = sum / (2 * BLUR_SIZE + 1);
}
}
}
算子库的编写者可能会采取对外层循环进行分块变换的方式对上述代码进行优化
void blur_y_tile(int const image[X * Y], int image_blur[X * Y]) {
for (int j = 0; j < Y; j += 16) {
for (int i = 0; i < X; i++) {
for (int k = 0; k < std::min(16, Y - j); k++) {
int sum = 0;
for (int t = -BLUR_SIZE; t <= BLUR_SIZE; t++) {
if (i + t >= 0 && i + t < X) {
sum += image[(i + t) * Y + (j + k)];
}
}
image_blur[i * Y + (j + k)] = sum / (2 * BLUR_SIZE + 1);
}
}
}
}
在我的个人PC下进行测试(clang -O3),保证结果相同的情况下,仅仅通过分块就让执行时间降低了一半以上。
[ RUN ] clang.blur_origin
[ OK ] clang.blur_origin (2513 ms)
[ RUN ] clang.blur_tile
[ OK ] clang.blur_tile (960 ms)
循环分块可以视为专家针对目标平台对算法进行手工优化的一个典型示例,除此之外还有各种各样的优化手段。
算子库的编写是一个人力密集型的工作,并且泛化性很有可能不好,表现在针对不同类的硬件平台、同一种硬件平台的不同代产品可能都需要专门进行适配;除此之外,极致性能优化的代码可能甚至需要内嵌汇编代码来达到更细致的控制,其代码可读性近乎没有,难以调试,依赖领域专家的经验。
该节所提到的手工算子优化更多的是为了极致压榨硬件平台的性能,与同学们在大一时算法课学到的算法设计有所区别。“手工算子优化”一般来说无法带来像冒泡排序到快排这种数量级的性能优化。
手写以及编译从来不是互斥的关系,在传统编译器时代,编译器+math库高性能是很经典的搭配。
面向CPU有名的线性代数算子库可以参考 Eigen,针对GPU的并行计算参考并行计算的章节。
问题
-
将 llama 3b 模型导出为onnx格式并用 onnx runtime 进行部署
-
profiling算子融合所带来的性能受益
-
结合汇编代码,尝试解释为什么gcc编译出的matmul算子性能是clang的十倍
-
解释为什么对循环进行分块可以带来性能的巨大提升
-
除了循环分块,还有哪些优化常见的优化手段,请使用代码举例说明;并且尝试将这些优化手段应用于blur算子,并且附上性能数据
-
异步内存拷贝相比同步拷贝有什么优势
-
调研如何分析一个矩阵乘法在单核心CPU上实现的的理论性能
-
请使用多线程在CPU上实现矩阵乘法,详细介绍在数据通信、计算任务划分等方面的优化
-
分析下述代码,
foo和bar函数哪个运行更快,为什么?如何优化foo函数……
#include <cstdint>
#include <iostream>
#include <thread>
struct data {
int a;
int b;
};
void add_a(data &global_data) {
for (int i = 0; i < 500000000; ++i) {
global_data.a++;
}
}
void add_b(data &global_data) {
for (int i = 0; i < 500000000; ++i) {
global_data.b++;
}
}
void foo() {
data data_x;
std::thread t1([&data_x]() { add_a(data_x); });
std::thread t2([&data_x]() { add_b(data_x); });
t1.join();
t2.join();
uint64_t sum = data_x.a + data_x.b;
std::cout << "Sum foo : " << sum << std::endl;
}
void bar() {
data data_y;
add_a(data_y);
add_b(data_y);
uint64_t sum = data_y.a + data_y.b;
std::cout << "Sum bar : " << sum << std::endl;
}
- 调研如何分析一个矩阵乘法在单核心CPU上实现的的理论性能
并行计算
题目背景
郭子是名震四方的 Gang Star,威名远播,在帮派里有几个亲信手下以及大批训练有素的普通小弟,亲信手下作为左膀右臂,可以独当一面替郭子分忧;而普通小弟则负责执行大量重复且细碎的任务,听从亲信的指挥,有条不紊地完成帮派分配的各项工作。作为一名讲究效率的老大,郭子深知合理分配任务和协调行动的重要性,他善于利用亲信们的智慧与普通小弟的数量优势,确保整个帮派运转高效、如同一台精准协作的机器…
作为幕后 Boss,郭子为了省去繁琐的协调麻烦,需要开发了一个人员管理系统,专门负责手下的调遣和任务分配,自动安排亲信和普通小弟的职责与工作负载,他希望通过这个软件可以大幅提升帮派的运作效率和响应速度,让每一次行动都能精准高效地执行
为此,他开始并行计算的学习之旅
回答问题
-
请了解 GPU 架构模型,包含:
-
抽象结构:Grid, CTA(Block), WarpGroup, Warp, Thread;
-
硬件结构:SM, Cuda core, Tensor core, Warp Scheduler
-
内存层级:Global Mem, L2 Cache, Shared Mem, L1 Cache, Reg file
-
-
GPU 和 GPGPU 的区别是什么
- NVIDIA GPGPU 的发展经历了从早期的 Tesla 到最新的 Blackwell 架构。在最近的几代 GPGPU 中(本文聚焦于 Ampere 和 Hopper 两代),它们在架构设计上各自具备哪些显著特点与优化方向?
-
对于 GPU 来说计算一个 a[0:127] = b[0:127] + d[0:127] 的过程 [见 TASK 任务]
-
什么是指令并行,数据并行,任务并行?
-
什么是 SIMD?什么是 SIMT?什么是 SPMD?
-
了解 CUDA 的编程范式,如何写一个简单的 CUDA 程序?
-
一个 CUDA 程序的执行过程是什么?
-
了解 CUDA 中的_global_ , _device_等的用法
-
了解 CUDA 的异步特性(CUDA Stream,CUDA Graph)
-
思考如何写一个简单的 Matmul,以及写 CUDA 程序会面临的问题(Bank Conflict, Warp Divergent)[见 TASK 任务]
-
引入 Cutlass (Cute),Cutlass 的使命是什么(类似 C++ STL),如何使用 Cute 简化代码
-
Cute 是如何解决线程 Layout 映射的?
-
了解一下 Cutlass4.0 (Cute DSL)
-
- 引入 Triton(Tvm,Tilelang) ,了解 Triton 想解决什么问题,如何用 Triton 写一个(Flash Attn, Paged Attn…)[见 TASK 任务]
-
请探究 Pytorch 算子 下降到底层 CUDA 代码 的过程(目前也可以下降到 Triton)
-
ThunderKittens[2] 是什么? ,有什么优点
TASK:
- Part1:CUDA 编程练习
- Part2: CUDA GEMM 实现
关于 Part2 的优化思路可以参考:GEMM - Part3: Triton Puzzle 实现
关于 Part3 的环境配置请参考Triton Puzzle
大模型推理
题目背景
当你打开 GPT,在问答框中输入你想要问到的问题,看到 GPT 进行短暂思考后,逐渐开始一小节一小节返回答复,最终你拿到了问题的回答…
回答问题
-
(先来点开胃菜热热身子
- 我们常说大模型训练和大模型推理,这二者有什么区别
- 什么是 Compute Bound & Memory Bound,这二者会影响哪些东西
-
Prefill & Decode & KV Cache
背景:
当你打开 GPT/deepseek/grok等应用,在问答框中输入你想要问到的问题,看到 GPT 进行短暂思考后,逐渐开始返回答复,最终你拿到了问题的回答。这就是用户所直观感受到的大模型服务过程。但实际上,在系统内部,这个推理过程可以拆解为两个阶段:Prefill 和 Decode
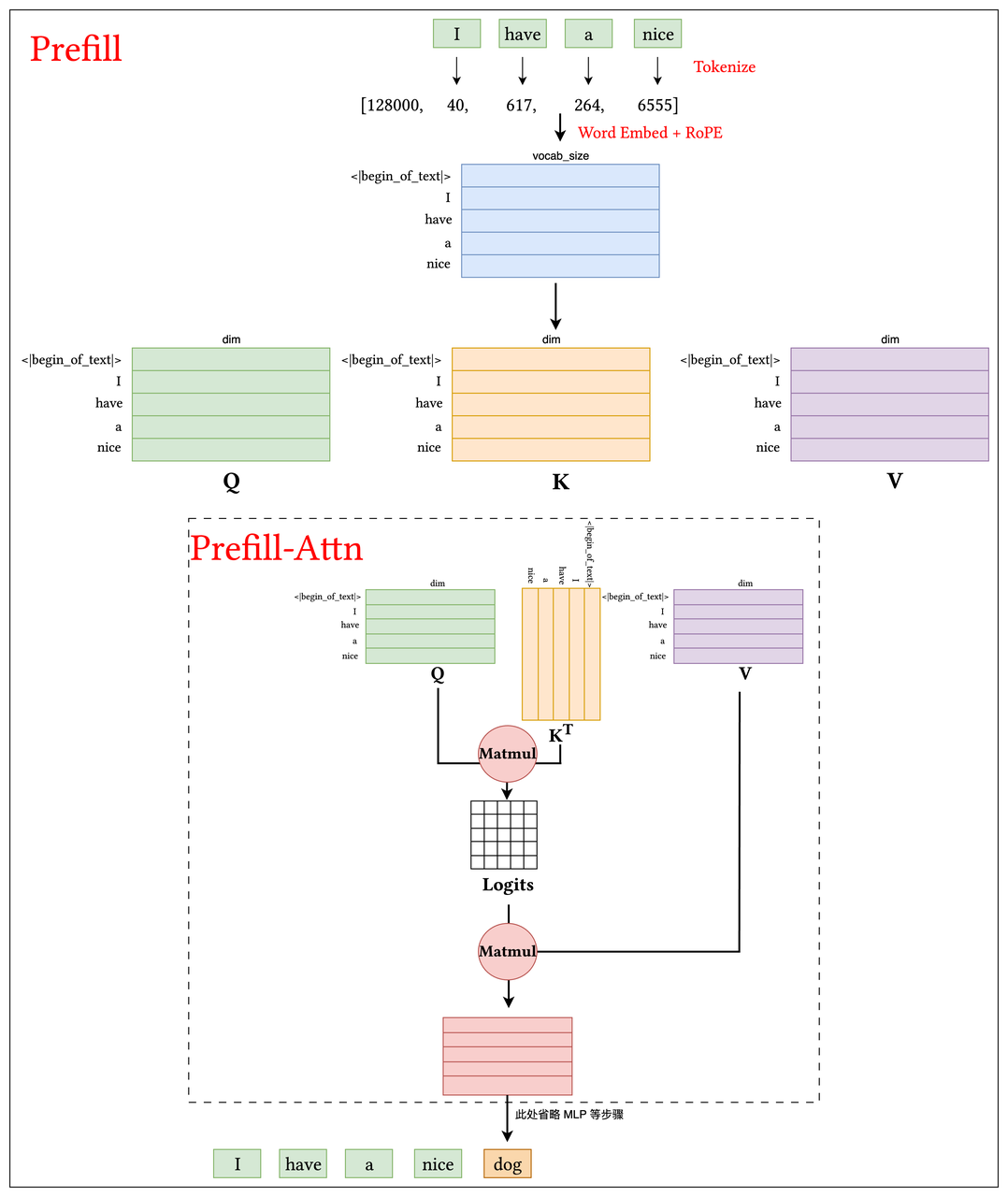
Prefill 阶段,模型会一次性读取并处理用户的全部输入,对这个输入进行 Tokenize、Attention、MLP 等操作。Decode阶段在 Prefill 的结果基础上,模型逐步生成输出,每次预测下一个 token,并将其反馈给用户,直到形成完整回答。
观察下图 prefill 和 decode 的过程(图像只画出了主要的 Attention 部分,省略了其他的内容),可以发现,由于 Transformer 的自回归特性,在 Decode 阶段所需的 K、V 矩阵几乎与 Prefill 阶段完全相同,唯一的区别是 Decode 阶段会在原有矩阵的基础上新增一个由最新 Token 生成的 K、V 向量(图中的 <dog>),这也就是 KV Cache 的由来了。换句话说,我们无需在每次 Decode 时重新计算整个 K、V 矩阵,而是可以将 K 和 V 分别进行存储,等到需要的时候取出 K 、V 就能省去计算,复用已有的东西。
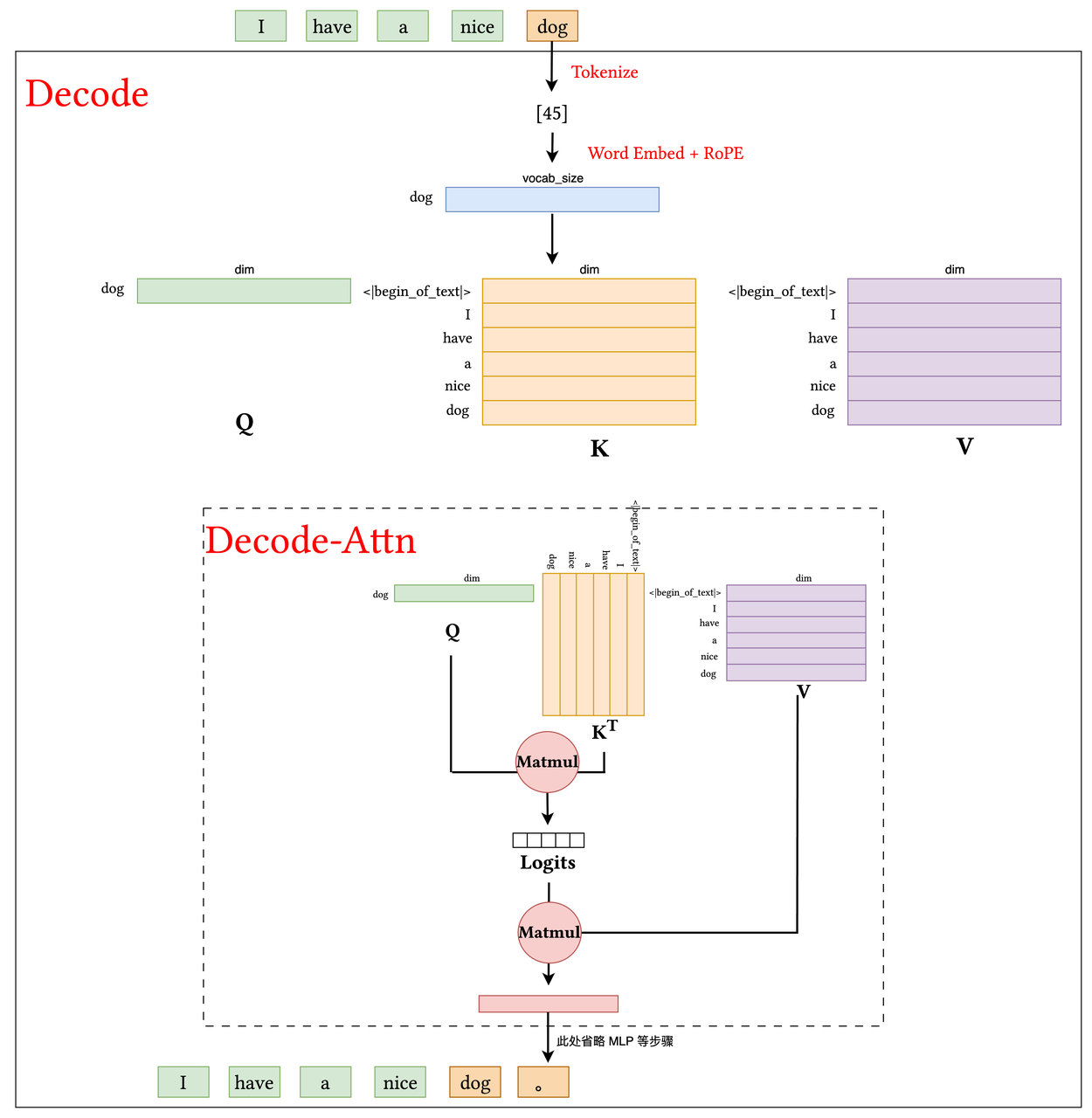
KV Cache 的引入带来了冗余计算的省略,同时也带来了新的问题,考虑下面的情况:
如果你手里有一块 32G 的 5090,在 Hugging Face 上拉取了一个 Llama 13-B 模型(B 是形容模型参数量的单位,1B = 10^9),我们假设模型权重是使用 FP16 来进行存储(即 2 字节),那么模型参数一共会占据大概 (13 * 10^9 * 2) = 2.6 * 10^10 ≈ 24.2 G 的显存。
PS :这里为了计算简单我们只考虑参数占据的显存,实际上显存的占用还有激活值,运行时库/框架自身的开销,以及如果是在训练时的优化器开销(比如 Adam 需要存储 FP32 的一阶、二阶动量)
这也就意味着我们只有剩下的 7G 来处理 KV Cache,很糟糕的是: KV Cache 的大小会随着 Decode 的进行不断增长。我们继续计算一下,如果我们的 KV 的 dim 设置为 5120,那么一个 token 所占据的显存大小为: 5120 * 2(K/V) * 2(FP16) = 20KB/token. 如果在同一时间,有 100 个请求传入,每个请求有 5000 token(即传入的 [BatchSize, SeqLen , Dim]= [100, 5000, 5120]), Prefill 阶段所需要的显存大约为 9.5G,已经超出了我们所能承受的范围…
如何在 KV Cache 的基础上进行优化,以降低显存占用并保证高并发请求下的稳定运行,成为了目前 MLSys 的一个研究方向。
Task:
-
过多的 KV Cache 除了会导致显存的开销之外,还会有什么缺点?(可以从硬件角度出发思考)
-
阅读论文:[2412.19442] A Survey on Large Language Model Acceleration based on KV Cache Management ,总结当前针对 KV 缓存的稀疏化方法
-
阅读论文:[2309.17453] Efficient Streaming Language Models with Attention Sinks ,尝试理解什么是 “attention sink” 现象?论文中是怎么处理的?
-
【Bonus: Sparse Attention】在常规的 Attention 中,Q 矩阵中的每个 token 都会与 K 矩阵中对应 token 之前的所有 token 进行内积计算 (causal mask),从而生成对应的注意力权重。但是这会导致 n^2 的计算复杂度以及空间复杂度,同时 KV Cache 的存储需求也显著增加。 对于长序列或高并发场景,这种复杂度会迅速占用大量计算资源和显存。为此,稀疏化 Attention 被提出,用于只计算部分关键 token 之间的注意力,从而显著降低计算和显存开销,同时尽量保持模型性能。
请阅读 DeepSeek 在 2025 年 2 月提出的 NSA: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention ,理解其中的稀疏化实现(算法+代码如何实现)
在上一节中我们使用了 Llama 13-B 模型占据显存进行举例说明,对于 13B 的模型占用显存已经达到了 24.2G,而常见的 LLM 通常秉持“力大砖飞”的理念,比如 DeepSeek V3 模型足足有 671B 的参数量(当然这里包含了 MOE 等稀疏结构),如此庞大的参数规模,使得运行这类模型往往需要依赖几十台 GPU 的分布式集群推理。这对计算资源提出了极高要求。为了在有限硬件上高效运行大模型,量化方法逐渐被广泛应用。
量化也就是通过将模型参数与中间计算由高精度的浮点表示(比如 FP32、FP16)压缩到更低精度的表示(如 INT8/INT4,甚至3 bit,1 bit),以此减少显存占用和内存带宽压力,同时加快计算速度(可以看看 NVIDIA A100/H200 等GPGPU 对于 int8/float16/float32 各类型分别的 FLOPS)。
但是读到这里相信大家有点疑惑了,我们都知道高精度浮点所能表示的数值范围和精度一定是高于低精度的(比如 FP16),那么为什么可以这样用更低位宽的 int8 甚至 int3 来表示更高精度的 FP16/32 呢?
这里我们通过Llama-3.1-8B-Instruct模型举一个例子:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import matplotlib.pyplot as plt
import os
model_path = "meta-llama/Llama-3.1-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
# print all types in stored weights
dtypes = set(p.dtype for p in model.parameters())
print("All dtypes in this model:", dtypes)
os.makedirs("weights",exist_ok=True)
for layer_name, param in model.named_parameters():
weights = dict(model.named_parameters())[layer_name].detach().cpu().numpy()
plt.figure(figsize=(8,6))
plt.hist(weights.flatten(), bins=100, density=True, alpha=0.7, color='blue')
plt.title(f"Weight Distribution of {layer_name}")
plt.xlabel("Weight value")
plt.ylabel("Density")
plt.xlim(-0.2, 0.2)
plt.savefig(f"weights/{layer_name}.png")
## 或者打印出表格
## plt.show()
运行完代码后请大家查看保存权重的分布图,可以发现一个非常简单的规律:虽然这些权重在存储时使用的是 FP32 精度,但它们的取值并没有充分利用整个数值表示范围,而是总体上近似服从正态分布,集中在某个较小的区间附近(-0.2, 0.2)
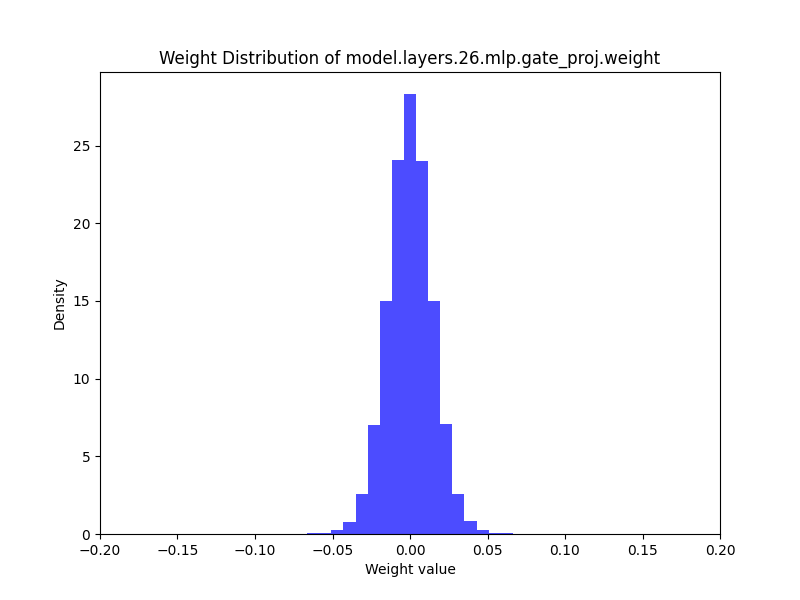
这就为量化创造了条件:既然权重大多集中在某个较小范围内,我们完全可以用更低位宽的数据类型来近似表示这些权重,从而在几乎不损失模型精度的情况下,大幅减少存储开销,实现显存占用的“直接腰斩”。
TASK:
-
阅读 [2103.13630] A Survey of Quantization Methods for Efficient Neural Network Inference ,调研目前流行的量化算法有哪些
-
量化分为训练时量化(Quantization-Aware Training, QAT)以及后训练量化(Post-Training Quantization, PTQ),这里我们主要关注 PTQ 方法。阅读下面的论文,总结两种方法的异同:
对于一个大模型来说,单块 GPU 往往难以满足推理所需的显存和算力,因此通常需要依赖 GPU 集群来协同运行。目前主流的大模型分布式推理方法有 Tensor Parallel(TP)、Pipline Parallel(PP),Data Parallel(DP)。不过,考虑到资源限制,本题并不会要求大家实际动手尝试分布式的初始化或通信计算。
TASK1:
- 阅读博客 https://zhuanlan.zhihu.com/p/613196255 ,详细了解大模型并行推理方法,给这三者的通信量由高到低排序(通信量 = 一次推理的通信次数*每次通信传输的数据量)
对于 NVIDIA 来说有专门的 DGX 服务器,专用于大模型训练与推理,可以装载有最多 8 张 GPU。其优势在于通过 NVIDIA 的 NVLink 和 NVSwitch 可以实现 GPU 之间的高速互联,从而大幅提升多 GPU 协同计算的效率和数据传输速度。因此,在实际集群推理中,通常会把 8 卡配置用于张量并行,让 DGX 内每张 GPU 都能享受高速互联带来的“加速红利”。
TASK2:
- 为了充分利用上机内资源,NVIDIA 开发了专用的通信库 NCCL GitHub - NVIDIA/nccl: Optimized primitives for collective multi-GPU communication ,请查阅资料理解其中的 AllReduce 算子和 AllGather 算子
引用
[1] Triton Code: GitHub - triton-lang/triton: Development repository for the Triton language and compiler
[2] ThunderKittens: [2410.20399] ThunderKittens: Simple, Fast, and Adorable AI Kernels