焦糖工作室是干什么的
是一个西点屋
焦糖工作室(Jotang Studio)是电子科技大学信软学院创新工坊的一个学生技术团体,主要活动地点在电子科技大学沙河校区三教507和403
焦糖工作室全部由本科生组成,在这里可以拓宽技术的视野,和小伙伴们一起开展课程安排中没有的技术实践,焦糖的目标是让每一位成员都能得到成长
2024招新活动安排
工作室永远欢迎对技术和团队热爱的新人!无论你是大一还是大二,都可以加入这次技术马拉松赛,并在这个过程中掌握技能和探索自己的方向,相信你自己,很多事情没有那么难。
- 为期一个月的技术马拉松赛 从2024.9.23日开始,到2024.10.23日截止
- 工作室招新面试阶段:在技术马拉松中达到通过标准的同学可进入工作室面试阶段
如果你不是萌新,可以将简历发送到邮箱admin@jotang.club(邮件命名格式:年级-姓名-简历,如:21-段衍凯-简历),我们将组建专业团队(误)对简历进行评析并在3个工作日内给与答复。
规则
- 完成任意题目后请将需要提交的内容放到新文件夹(命名格式为:题目序号-姓名,如#2-段衍凯),最终将所有文件打包(命名格式为:年级-姓名-发送日期-做题题号,如:21-段衍凯-9.14-127)并发送至邮箱 admin@jotang.club 。
- 题目提交次数不限,以 最后提交版本为准。 马拉松截止时间为2024.10.23(23:59)
- 每道题都需要提交记录了学习过程的markdown文件,如果要求代码,请上传至Github并将访问链接一同提交。如果你还不知道什么是Markdown和Github,请先做科普福利题#1 啥是Git和#2 Markdown
- 招新对题目数量不做硬性要求,你可以深入一题,体现你的技术深度,也可以“我全都要”,探索自己的兴趣方向。
- 如果需要与我们交流(比如题目太简单了,题目出现错误等等),请同样写下你的具体想法发送邮件到上述邮箱,或者在招新群中找到对应的出题人私聊
- 截止日期后约半个月的时间里,我们会根据 题目的完成度 和在 Markdown文档记录与细节 给出评分表,并将其汇总为一个总评分表,达到通过标准的同学可以进入面试阶段
- 科普福利向题目是帮助同学们热身和入门学习的,请一定至少选择一道代码技能向题目完成,题目的完成度最重要
- 当你发现有些帖子打不开或者下载不了,建议更改域名中的“d.jotang.party”为“d.jotang.club”,这是我们论坛迁移的bug,正在修复,请您谅解
- PS:
- 诚信是Jotanger的底线,一旦我们发现解答中存在严重的copy现象,无论技术力如何,我们都将拒绝您的加入
- 在马拉松过程中,如若题目有表述不清或其他问题和疑问,请及时反馈给出题者。出题者在招新群中统一以 2024#题号-姓名 (如2024#1-段衍凯)命名
- 焦糖时刻欢迎各位萌新在群里提问,也鼓励同学间互帮互助。但焦糖依然希望同学们养成在提问前先自行谷歌的习惯,因而对于一些能直接Google
百度出来的答案,焦糖学长们可能不会全部解答,望理解。
题目类型
- 科普福利向
- #0 Let’s Warm Up! :科学上网
- #1 啥是Git: Git版本管理工具
- #2 Markdown:通用的文档格式
- #3 Linux & WSL & Docker:配置环境/操作系统
- #4 MakeFile & CMakeList : C/C++代码构建工具
- 代码技能向
#0 Let’s Warm Up!
你好,欢迎来到这里!这个部分是 JoTang Studio 招新的一系列预热题目!焦糖工作室为202[1-4](论正则表达式的妙用)级的同学精心准备了兴趣引导和前置技能题目。但是不要担心,我们的题目难度已经过严谨考虑和调整,并且我们并不要求全部完成(选择自己感兴趣的方向深入学习;或者尝试多个方向)。焦糖工作室希望,你可以通过这些题目,初探开发和软件的世界,并能够发现自己感兴趣的方向。
萌新:这引导看不懂啊?这链接为啥打不开?这些名词啥意思啊?这报错了咋整啊? dalao:Let me Google that for you 萌新:…卒
不要慌嘛,焦糖是一个萌新友好型工作室,我们会先带你点亮前置技能点。
搜索
对于不同领域的问题,需要灵活运用不同的搜索引擎。
比如我们推荐使用 Google 作为通用搜索引擎,使用必应/百度(在你搜索广告的时候使用)作为中文搜索引擎。yep!23年与以往不同的是咱们有 chatgpt poe 可以用捏(b站上有很多教你如何注册chatgpt账号(前提是你得会科学上网)和 不通过科学上网也可以访问chatgpt的教程哦
这里推荐一个聚合的搜索引擎网站:虫部落快搜
如果你想掌握更高级的搜索技巧,这篇文章也很简单易懂:搜索引擎的一些高级搜索指令
但除此之外,我们也可以发起针对性的搜索。
比如如果你在编程过程中遇到了奇奇怪怪的难以修复的BUG,你可以考虑使用国内的CSDN论坛搜索,也可以使用StackOverflow(推荐)它们都是优秀的开发者社区,在特定的领域困扰了你很久以至于你怀疑这是一个bug你还可以在github对应的项目主页上提issue。
如果你对于“为什么无法访问 Google”有疑问,欢迎看看我们为你准备的科普文档:深入理解GFW
提问
虽然搜索引擎的效率远逾言辞,但有时,光靠它的能力也有未能解决的问题,我们需要向别人提问。如果是在社区(discard/github/stackoverflow/reddit…)提问,为了更高效地获得可靠的回答,你可以需要一些提问的技巧:
ryanhanwu/How-To-Ask-Questions-The-Smart-Way 本文原文由知名 Hacker Eric S. Raymond 所撰寫,教你如何正確的提出技術問題並獲得你滿意的答 案。 - ryanhanwu/How-To-Ask-Questions-The-Smart-Way
计算机体系漫游
萌新刚上大一的时候很多时候会觉得想学技术又不知如何下手(毕竟也不是所有人都是从小学都开始学习c语言、初中开始打oi、高中为开源世界做贡献、刚上大学就有十年编码经验的技术大佬),对于计算机软件的认知局限在互联网的前后端,其实计算机领域有非常非常的多哦,只是这几年互联网领域比较热。对于刚接触计算机相关知识的小伙伴,墙裂建议抽时间了解一下计算机领域的导论知识哦 为此Jotang为各位精心准备了计算机导论大合集 计算机世界漫游 学习这些课程或许不会对你的编码能力有很大的提升,但是可以让你学习到
计算机是从哪里来、要到哪里去 ! 和喝酒时的时候关于计算机可以多吹几句牛
你的任务
- 迅速获得获得一台计算机的使用权。
- F**k the GFW.(获取Google等网站的访问权限)
- 闷声发大财,本题无需提交。
- 漫游计算机导论(如果你觉得这是一件有意义的事情)
划重点
- 如果同学你没有办法回到家中,你可以考虑去网吧(一起来网吧编程!你小子最好是去编程)。如果你不太想去网吧,那么你可以考虑一下购买一块树莓派+外接屏幕和键鼠的方式练习使用Linux系统。如果你想尝试用平板/手机代替电脑。你的下一台电脑,何必是电脑,也欢迎与我们交流。
- 我们强烈建议你马上拥有一台个人笔记本,赢在起跑线!赢在人生路!(逃
- F**k the GFW(科学上网) 对于咱们计算机科学家来说十分重要捏,请将这件事情放在首位
#1 啥是Git
01背景
第五次收到某同学用 QQ 发来的的 debug 请求和zip压缩包时,我陷入了沉思,于是有了这道题。
还未接触太多代码的你可能很难意识到Git的作用,因为当前的一道习题对应一个代码文件,而且大多数时候也只是你一个人在编辑,在此时Git并不能带给你颠覆性的开发体验,但是对于多人参与的代码量稍大的项目而言,没有版本控制工具是难以想象的。(顺便一提,想一个人开发大型软件是不可能的哦,合作能力甚至可以说是软件工程领域最核心的能力之一)
想象一下下面这些场景:
- 当你需要编辑一个文件时,如果不想产生冲突,其他人需要避免操作这个文件,要等你完成修改后再把最新版流转给ta。
- 还是这样的场景,当ta修改了项目后,如果你又要进行编辑,除非ta告诉你,不然很难确定修改的位置,更难评估对你目前任务可能造成的影响。
- 当你的更改需要进行取舍的时候(甲方:我觉得还是第一版比较好),可能需要在多个版本的完整代码中比对,如果没法复原,这无疑令人绝望。
- 当你进行的更改导致了严重的bug,或是不得不放弃,你也很难快速地回溯到原先的状态。
显然,没有版本控制系统,这些都会在项目开发过程中频繁出现,严重影响我们的开发效率和身心健康。
所以痛心疾首地安利 Git 之后,希望每一位同学都能够掌握 Git,并且习惯使用它来管理自己的代码。
关于什么是Github
Github是世界上最大的开源协作社区和在线Git远程仓库托管服务提供商,是运用Git思想来工作的一个商业网站,在2018年被微软收购后,Github的私人远程仓库服务也开启免费了,你可以上传自己的项目代码到远程,世界上的其他人可以搜索到你的代码,和你参与协作。又或者你重装了电脑,可以直接重新从远程仓库下载原本的代码,无需额外用存储设备保存。
除此之外,凝聚了无数人类智慧精华的众多开源项目都在Github上进行版本管理和迭代。如果你很好奇一些技术(比如前端的facebook/react 2、vuejs/vue 后端的apache/kafka 1 、apache/zookeeper 1等项目)的当前进展和未来规划,或者发现了代码里的bug,都可以通过提交issue或发起Pull request来加入开源社区的共建!
准备
-
准备git环境,尝试一些本地的Git操作
(墙裂建议首先配置好linux环境。wsl、虚拟机、双系统等linux环境都可以让你更加方便快捷的完成后续的所有任务)
Git 安装配置照着教程慢慢走下去吧~你不一定要将每一个知识点背下来,而是你要知道git有这样的机制,等你真正需要用到的时候知道去哪儿查资料(学习很多工具的时候都要以这样的学习方式去学习哦
-
学习使用Github远程仓库,将本地的项目提交上去吧
-
Git工作流
十分钟学会正确的github工作流,和开源作者们使用同一套流程 19
git工作流是大家使用git作为版本控制工具进行软件开发遵循的一种规范,能够方便大家对项目的管理。
任务
- 用本地化Git来管理本次招新马拉松的题目回答项目文件吧!如果你可以写一写遇到的问题或者学习的过程就更好了~
- 注册Github账号,并将你在本次招新马拉松中所做的题目提交上去吧!如果
commit message写得比较规范或者项目文件管理比较清晰可以加分哦~(记得建立远程仓库时选public不然我们看不到) - 拥有自己的github账号后可以试着完成github上的学生认证(这便宜不占白不占),认证后可以享受的其中一个最大的好处就是能够实现copilot自由!!从0开始的github学生认证并使用copilot教程
- 进阶题目 有自己的博客是一件多么令人兴奋的事情啊~ ,使用 GitHub pages 免费搭建一个博客吧!(啊?你问我怎么做?请看第0题自行搜索)
如果你更喜欢搭建包揽前后台以及数据库的动态页面博客,比如这样的 59(强行给学姐博客打广告🤣),可以自行探索~
备注
由于GFW的存在,最近两年Github的国内访问速度和稳定性都有明显下降,所以我们推荐你使用一些方法(比如第零题的任务)进行加速。另外, Github也提供了桌面端程序Github Desktop 14 可以在一定程度上避免上传和下载遇到的奇形怪状问题。
如果你已经成功配置好了wsl,那么可以参考文档进行代理配置。 为 WSL2 一键设置代理 在 WSL2 中使用 Clash for Windows 代理连接
如果实在做不到访问Github来完成题目,也可以将远程代码托管网站换成Gitee 4
但是如果可以还是非常建议使用github而不是gitee,关于github加速你还可以检索一下如何让终端也走代理(前提是你已经掌握科学上网)
题外话
- Github 的 private repo(私有存储库)已经对个人用户免费了,所以不用害羞哦!
- 本题旨在带你了解 Git 和 Github,发现更大的世界。哪怕对 Git 和博客不感兴趣(博客倒是可有可无,但是不用git是不可能滴),也希望你能注册并探索一下 Github 这个世界上最大的开发者社区,没事多逛逛 Trending 6 ,star 些你感兴趣的项目。
- 提交的时候记得附上你的 Github 主页和博客链接哦!
#2 Markdown
背景
多年以后,阿卷再一次打开邮箱,还会想到那个与工作室小伙伴们兴高采烈地打开招新题收件箱的那个遥远的下午,在看到满屏幕的.doc格式的word文档陷入了沉思,欲哭无泪的表情在他脸上久久不能散去(误
而当年,还是小白的hoshi也曾痛苦地改着word格式,字体、字号、图片布局各种bug此起彼伏
你是否也曾被被word中各种纷繁复杂的格式问题困扰得想砸电脑(bushi)
好消息!!看看简洁的Markdown吧
Markdown 是一种轻量版文本标记语言(萌新:什么是文本标记语言?)
Markdown可以让你用写txt记事本的写法写文章,但却可以生成不亚于word文档的好看的排版,在计算机世界中,遍地是markdown格式的文档,无论是Github里各个项目的README,还是优秀的工程师的博客,都是由Markdown书写,除此之外,markdown在简书、知乎以及很多论坛中得到应用。
Markdown并不是一个软件,你可以使用任何编辑器书写markdown文档
注意:本次技术马拉松中你提交的所有文档都应该是markdown格式哦
一起来学习Markdown吧!
- 菜鸟教程-Markdown 114
- 一个实时预览的markdown在线编辑器 81 41
- Typora编辑器 29 你可以下载它的0.11.18 beta版 是免费的 Typora for windows — beta version release 42 32 如果你想有更多功能可以购买价格$15的付费版(它确实很值得~)
- 飞书云文档 22也是支持markdown的,也还是非常好用的
任务
- 闷声发大财,好消息是本题也不用提交
- 坏消息是你所有的题目都需要以markdown的格式提交(顺便一提源代码请放到github仓库上并且在markdown中附上github项目仓库的链接
备注
如果我没记错的话,昨年收到了很多markdown里面的图片路径是你本地电脑的图片路径。阿sir我怎么去你本地的电脑访问图片呀(切记不要使用本地路径,收到文档如果图片无法查看我们将无法进行判断打分!!)。如果你不想使用图床,打包的时候请将图片一同打包(务必使用相对路径哦)
关于什么是图床和相对路径请自行查阅!
#3 Linux & WSL&Docker
题目背景
学期开始,想要加入 Jotang 工作室的小马面对各种招新题,早已跃跃欲试。为了完成招新题,小马先是安装配置了 Python 开发环境;转头捣鼓 Java 时,又配置好了 JDK;配置好了 Go 的开发环境后又去安装了 Node 包管理器。
问题来了:
不同的框架兼容不同版本的开发环境出现兼容问题时,这时小马看着已经变成各种语言各种版本号形状的环境变量参数(并且因为 **软件园的软件 一不小心弄的电脑满是病毒),早已欲哭无泪。而 Windows 又是平时的生产环境,不方便全盘清空重装,这时要怎么办呢?
这时 WSL2 闪亮登场,他能够在 Windows 环境下虚拟出一个带有完整 Linux 内核的开发环境
问题又来了:
WSL2 的 GUI 配置困难,而且有的同学就是喜欢用带有 GUI 的发行版。命令行虽好,但是同时拥有 GUI 不香吗?
显然此时只有完整的虚拟机能满足小马的需求了,在虚拟机下,小马得到了:
- 便于配置各种语言的开发环境(包管理器 37 yyds
- Linux下更方便地处理不同开发环境的版本兼容
- 便于试错,配置炸了的话随时可以清空整个环境不用担心生产环境数据丢失
- 满足小马的洁癖与强迫症
- 方便的备份与回滚
- 开源的操作系统!
至此,小马可以开开心心地做各种招新题目,再也不用担心他心爱的 Windows 环境变成各种形状了!(事实上是他以后再也没使用过windows做开发捏
还有一件事,如果你想让审题人在他的电脑上以相同的环境运行你的代码(咱就是说也不能把审题人的环境搞炸是不是),你可以学习一下docker的使用,具体要求在加分项里面有哦。
有了linux系统后你会发现
题目内容
任务(三选一)
- 安装配置 WSL2 的 Ubuntu(或者是任何主流的linux发行版 但是请不要安装centos) 发行版(酷酷的大黑客
- 在虚拟机软件中安装配置 Ubuntu (或者是任何主流的linux发行版 但是请不要安装centos)发行版(gui交互逻辑非常香!
- 安装 Ubuntu 和windows双系统 (稍微有点硬核咱就是说 不过双系统对于显卡的支持会更好,对于想在本地训练模型的机器学习童鞋会更加友好哦
对于萌新来说还是建议大家使用Ubuntu ( lts 是 long time support的缩写 意思是不会出什么大问题的版本) ,并且中文互联网下资料也巨多无比
对于想要折腾的童鞋可以看看 计算机世界漫游 38 的linux节。
选择哪条分支根据个人兴趣以及需求来即可。
当然你也可以全都要(小孩子才做选择),毕竟自己真正喜欢哪一个是通过比较得来的。
安装完linux不知道下一步该何去何从可以参考一下第四题捏。
加分项
- 通过
VScode的Remote插件连接至你的虚拟机 / WSL2 和 了解windows下xshell的使用 - 配置好基于
SSH密钥的免密的远程服务器登陆 - 学习docker的使用并且将后续你提交的所有题目的项目打包放到
dockerhub上(请写好详细的readme.md并且提供一键运行的脚本)方便学长检查你的代码一键运行捏,非常方便就能还原你在本地的效果。这条是非必需的哈,请不要在这上面投入太多时间
划重点
- 除非你开发windows应用程序或者是java这种跑在虚拟机(咳 与本题中指的虚拟机不是同一个概念哈)上面的程序,不然我们墙裂建议你使用
linux作为你的第一开发环境(做到这一点就已经遥遥领先了 - docker是非常有用的工具,不过对于咱们学生来说可能需要用到的时候不是很多。你可以选择性了解
提交内容
- 每一步的截图
- 文字说明
- 个人感想
以上内容通过 Markdown 格式的文档提交
参考资料
- linux发行版的区别与联系 28
- The Reasons Developers Prefer Linux Over Windows Are Why EVERYONE Should Use Linux 20
- apt包管理器 19
- vi/vim linux下必须掌握的文本编辑器 24
- ssh连接协议 25
- 虚拟机网络模式 16
 Docker概念,工作流和实践 - 入门必懂 15
Docker概念,工作流和实践 - 入门必懂 15
#4 MakeFile & CMakeList
单文件编译
萌新小虎正在埋头苦做焦糖招新题,刚刚接触c语言的他对于代码的世界非常感兴趣,于是趁热打铁点开了Vscode,写下了他人生当中的第一个C程序
#include <stdio.h>
int main()
{
printf("Hello, World! \n");
return 0;
}
保存为hello.c文件之后,接下来在终端中输入命令
gcc hello.c
接着他发现多出了一个 a.out的可执行文件
在终端中继续输入
./a.out
终于他在屏幕上看到了打印出的Hello, World!
其实在输入 gcc hello.c 后,代码从原来的C程序到最后的可执行程序经过了许多环节
预处理
在编译器拿到我们的源文件hello.c之后,会将这个文件进行预处理,简而言之,预处理大概做了三个事情
- 替换 #include
- 替换宏
- 条件编译
gcc -E demo.c > demo.i
编译
所有的文件都处理好了之后我们才开始编译,编译的最终目的就是将原本的C代码转换到最终的可以实际跑在计算机上的汇编代码(x86,arm,riscv),它的工作是检查词法和语法规则,所以,如果程序没有词法或语法错误,那么不管逻辑是怎样错误的,都不会报错,这可能会解释一些同学写的程序在编译后没有问题,但是实际运行会报段错误这类的错
gcc -S demo.i
汇编
汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件
gcc -c demo.s
objdump -d demo.o
链接
上一步的汇编,我们通过objdump可以看到,我们调用的库函数其实他的地址不是真正的地址,而是一种相对于文件开头的偏移地址,那链接的目的之一就是将这些变成真实的地址
- 静态链接,程序中使用的库文件的代码直接编译进程序本身,这样做的好处显而易见,程序不再需要依赖外部的库文件,这也解决了程序猿口中本地能跑但是外部环境就不能跑的问题,但是缺点就是可执行文件会膨胀的非常大
- 动态链接,动态链接在链接阶段不进行链接, 等到程序运行时才进行链接, 也就是说 把链接这个过程推迟到了运行时进行
gcc memory_demo.o
//系统会默认去为你链接c库
//默认情况会是动态链接
gcc -static demo.o
多文件编译
小虎成功运行单文件程序后,心中出现了一个疑惑,如果自己有多个文件需要进行编译捏?
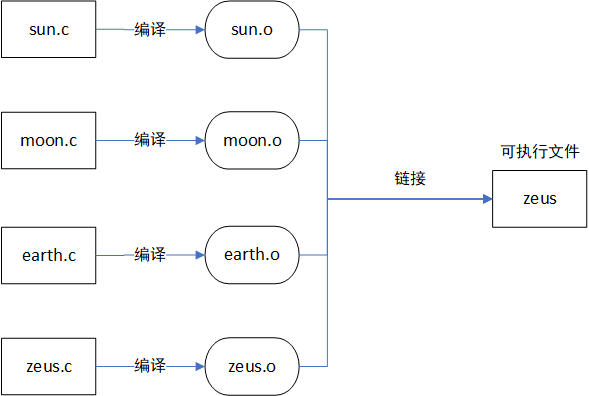
这样的方式你修改了什么就只用将修改了的单个源程序重新编译,并且链接
//多个源文件链接成一个可执行文件
gcc -c add.c -I./include
gcc -c hello.c -I./include
gcc -c mul.c -I./include
gcc add.o hello.o mul.o -o hello
//修改了mul.c文件
gcc -c mul.c -I./include
gcc add.o hello.o mul.o -o hello
MakeFile
小虎学会了基础的多文件编译后非常开心,想要大展身手,于是他去github上拉取到了一个项目,发现光是C文件就有几百个,如果自己要逐个通过命令行的方式对他们进行构建,可能一天也搞不完,于是在询问gpt后,他了解到了MakeFile
讲完了单文件的编译过程,那如果是一个大型的项目,有很多不同的文件,甚至的不同语言一起组合,如果是每一个文件都需要这样手动输入命令行,那未免有点太坐牢了,如果你每次修改想要查看运行结果的变化,就需要将对应修改的源程序重新编译然后再链接到一起
所以这个时候人们想出来设计一个方便的脚本,能做到只输入一行或几行命令就能完成上述的编译汇编的重复工作,同时他能帮我们识别出哪些文件是修改过的,这样再次make的时候就只需要编译修改过后的文件,而不需要全部重新编译,这就是MakeFile,可以参考下面的链接学习如何读懂和写出基础的makefile(注:学习makefile的基本使用就行(别学太深了,这玩意以后你也不太会经常用到,毕竟咱们有cmake用))
不过他也有很多的缺点 需要我们自己来理清楚其中的依赖关系 而且不是跨平台的
- 缺乏可读性:Makefile 文件通常比较难以阅读和理解,因为它们使用自己特定的语法和规则。
- 不够灵活:Makefile 通常需要手动编写,并且不够灵活,难以处理复杂的依赖关系和项目结构。
- 不支持跨平台:Makefile 通常是针对特定平台编写的,因此在其他平台上可能无法正常工作。
- 难以维护:由于 Makefile 通常比较复杂,因此很难进行维护和修改,特别是在大型项目中。
Cmake
讲完了MakeFile,cmake的出现,进一步的简化了构建的难度,通过使用MakeFile,虽然编译变得简单了,但是这个makefile也是需要你自己来写的啊,makefile的可读性差代表着需要自己来维护和写很困难,cmake的出现可以说解决了这一个问题,并且cmake是跨平台的,话不多说,我们直接举一个例子
include_directories(${CMAKE_SOURCE_DIR}/include/backend)
#用于向项目添加头文件搜索路径。这意味着在编译时,编译器会在这些目录下搜索头文件。
add_subdirectory(${PROJECT_SOURCE_DIR}/yacc)
#指定的目录添加到构建中。这通常用于将项目分解为多个较小的部分,每个部分都有自己的CMakeLists.txt文件。
target_link_libraries(SYSY-compiler Yacc Lib Backend opt Analysis)
#命令指定了SYSY-compiler可执行文件需要链接的库。这意味着在链接阶段,链接器会搜索这些库
一般过程:
- cd到项目的顶层目录(该目录下有目录项CMakeLists.txt)
- mkdir build && cd build
- cmake …(…指的是上一层目录) & make/ninja(Ninja是一种小巧且快速的编译系统,代替GNU Make和它关联的Makefile)
cmake /PATHTOSOURCE -GNinja -DCMAKE_BUILD_TYPE="Debug"
这个时候我们就得到了一个可以执行的项目
CMake的本质
CMake的本质上其实也是Makefile/ninja或者是一些其他的工具,只是CMake可读性更好,并且是与平台无关的
提交任务
- 详细了解一个C文件到一个可执行的文件的全部流程
- 在提供的github仓库中完成指定任务 =>Task
#5前端
前情背景
焦糖中的几位有志少年成立了一家AI初创公司:OpenJT。在高薪和原始股的诱惑下,你毅然决然的加入Open JT。现在你作为一名即将加入企业的新人,也想用所学前端知识,为公司做出贡献。
前置技能&学习工具
- VScode:写前端推荐用这个,有许多好用的插件拓展
- 推荐较系统视频课程 :某站黑马程序员/小甲鱼
- 推荐速成视频课程 :traversy media
- 各种文档 Bootstrap, Vue, ECharts, elementplus, vueuse,elementUI
- 技术论坛:CSDN / Stackoverflow
总体要求
以下题目意在帮助大家复习并将知识运用到实践中,故并非所有要求都必须达到,根据自己所学的程度尽力即可。请大家注重整体项目构建能力,并非每个细枝末节的知识点,考察各位的开发能力,并不反对使用ai工具辅助开发。另外,前端开发是一项进化非常快的技术,鼓励大家使用的较新的技术去提升开发效率。具体要求:
- 做题时鼓励用Markdown文档记录学习or做题过程。可以帮助我们打分。
- 不论题目完成到什么程度,请务必将最终网页部署到互联网上。(可使用 netlify 、vercel 等工具)
- 请将项目代码及相关Markdown文档上传到github仓库,按照题号划分文件夹。
- 大一同学若完成前两题,最后一道作为附加题。大二同学则尽全力完成。
题目一
一个公司的宣传网页就是一个企业的官方门面,好的宣传网页可以大大提高企业的知名度。国内外有许多官网作品参考,比如科技公司:Apple,微软,英伟达;消费品牌:法拉利,香奈儿;国内的华为,字节跳动等。建议在动手之前先广泛参考范例网站的配色思路,排版方式,积累审美经验。相信会对你设计网站有很大帮助!
为AI公司OpenJT做一个官方宣传网站,向用户展示我们的AI品牌。要求如下:
- 网站的布局风格可以自由发挥,鼓励参考现有主流品牌的官网寻找灵感。但不允许照搬风格
- 需要实现一个顶部导航栏,在页面下滑时固定在顶部。
- 建议将文字和图片等多媒体形式相结合去展示OpenJT。(图文部分可以自由发挥想象
- 可以加上一些动画效果与用户交互使页面不再单调(如鼠标浮动等等)
- 实现一个轮播图,图片可以自动播放,用户也能点击按钮自动切换。
- 可以在网页中加入图表这一元素。(如体现OpenJT用户量的增长)
题目二
22年末,ChatGPT横空出世。大语言模型以其强大的语言理解能力,出色的多任务适应能力,成为了炙手可热的科技产品。OpenJT作为一家AI初创公司,即将推出属于焦糖的大语言模型JoTangLM。现在需要你的帮助,为我们的大模型做一个前端交互网页供用户使用。
如果你对大模型了解较少,或者还未使用过。可以尝试几个国内的免费大模型(如Kimi,文心一言,智谱清言),和多模型集成网站(如Poe,nextchat等)
参考你喜欢的对话ai界面,发挥创造力,实现如下功能要求
- 实现最基础的多轮对话功能。在没有调用大模型之前,先用其他方式模拟对话。
- 允许用户创建多个会话。实现创建新会话,切换会话,删除会话的功能。
- 向用户提供个性化调整的功能, 考虑页面交互的功能性和合理性(即设置几个用户能够个性化调整的配置,例如网页配色,调整ai回答的长度,ai模型的参数)
- 使用本地储存,例如localstorage等方式,实现保留历史对话的功能。
- 注重用户体验, 考虑配色和布局的美观性, 布局与操作应该合理, 跳转逻辑要考虑可能出现的场景。
题目三
能够做到这里,相信你已经拥有出色的前端开发能力。现在更进一步,将我们的网站变成现实!
这一节对于大一的萌新有些难度,是你们的附加题。大二必做。
- 学习api请求的相关知识, 发送http请求,真正的向各开源模型请求数据, 实现完整ai对话功能,api接口资源示例(仅作为参考,非强制): DeepSeek, 通义千问, 文心一言, Kimi,智谱清言,chatGPT
- 所有你知道的功能都可以加上去(大胆发挥你的想象!), 例如预设对话, 流式输出, 不同话题分离, 整体记忆, 甚至语音与图像生成功能
- 网页应该具有普适性, 要求实现尺寸自适应。在任何屏幕比例下,包括移动端, 都应该有合理的布局方案
#6后端
Task0: 拥有你自己的服务器
背景
作为软件工程的一名学生,阿卷在开学后不久就了解到了git的神奇和强大之处。git在管理文本文件领域的能力十分强大,但在管理多媒体文件如图片、视频等时则并不是很方便。阿卷希望能够利用自己所学的知识,将自己的多媒体文件(当然也包括文本文件)存储到自己可以随时方便访问的位置。
在互联网的世界里,一台服务器至关重要,你可以在上面存放属于你自己的所有信息,你可以将自己的网站或者资料分享给在计算机网络世界中的所有用户
在如今的互联网世界中,每一个你所登录使用的Web/App背后都有一台强大的服务器。获取服务器,学会基础Linux指令开发是进行软件工程开发的第一步,现在就开始去获得属于你自己的服务器吧
!!!注意!!!:本题有两个分支,分别为Java方向和c++方向。选择本题的同学至少选择一个分支完成即可,感兴趣的可以继续进行深入了解。当然,都做完也是可以的哦🥰
要求
1.获取你的服务器
阿里云免费试用 - 阿里云 (aliyun.com)(这里是试用教程:ECS试用攻略-阿里云帮助中心 (aliyun.com))为新用户提供一台试用期为6个月的服务器,其配置可以支持你完成本题。你也可以选择你喜欢的华为/腾讯等购买一台服务器。
注意,不要给你的服务器设置过于简单的密码,否则其可能被不法分子扫到并进行滥用*(学长的惨痛教训)*
2. 对服务器进行基本操作
学习一些基本的Linux操作指令(参考资料:Linux常用指令 40),并在服务器上进行实操。实操内容可以参考下面的小测验
加分项
- 了解Linux的目录结构和文件结构
- 尝试其他类型的Linux指令,如进程管理、文件编辑、系统管理等,对日后配置服务器有很大的帮助
分支1 Task1: JavaWeb
拥有了服务器后,阿卷开始着手完成自己的计划。综合各种资料后,阿卷选择了java作为开发语言。
要求
基于你的服务器,实现将指定文件上传到服务器的接口。推荐使用SpringBoot框架+Mybitis。
对SpringBoot的学习,可以参考官方网站:Spring Boot 中文文档 (springdoc.cn)。你也可以在w3school 在线教程了解你想要了解的关于网站的知识。
可以使用Postman对你的项目进行测试。请对你所写的后端代码给出基本的测试报告。文档、代码格式都会计入评判标准
由于这部分内容较为庞杂,可能会涉及到Java基础、http请求、json格式、数据库的使用等,大一的同学如果没法全部完成,请详细记录你的学习过程,能体现出自己的独立思考更好
加分项
- 部署在服务器上,并给出可访问的公网链接(如果没有能力做简单前端页面可以只给出接口链接)
- 详细的代码注释和代码规范
- 规范的说明文档
分支1 Task2: 文件管理
在上述功能的基础上,阿卷仅仅是把想要的文件一股脑扔到自己的服务器上,并没有实现文件的“管理”功能。面对堆积成山的、文件名不知所云的文件,阿卷陷入了沉思,他决定要给这些文件添加管理系统。
要求
- 了解当下主流操作系统所采用的文件管理格式,简述他们的核心思想
- 为你服务器上的众多文件添加文件管理的相关功能,包括但不限于:根据文件名/日期查询文件、删除文件、创建(多级)文件夹对文件进行管理……
加分项
- 部署在服务器上,并给出可访问的公网链接(如果没有能力做简单前端页面可以只给出接口链接)
- 在文件管理时,将选中的文件展示在浏览器界面上,并提供下载方法
分支1 Task3: 安全管理
不对各种接口进行封装意味着互联网上任何人都有可能从中提取、篡改数据,甚至植入恶意连接等,这是十分危险的行为。任何一个知道你服务器接口的人都可以随意查看上面的内容,甚至将其为自己所用。因此,阿卷希望实现一个用户系统,拦截一些不健康的访问请求。
要求
- 增加用户系统并实现一个登陆接口,登陆成功返回token
- 对上述接口实现鉴权,未登录则拒绝访问
加分项
- 同时实现注册接口
- 对用户查看服务器上的文件实现权限控制,即用户可以选择上传到服务器的内容是否进行公开
- 部署在服务器上,并给出可访问的公网链接(如果没有能力做简单前端页面可以只给出接口链接)
- 详细的代码注释和代码规范
参考资料
分支2 Task1:C/C++实现回声服务器
勤奋阿卷在后端的学习中已经如痴如醉,使用各种框架完成数不胜数的复杂业务逻辑也是得心应手,但每每停下思索,总会有这样的问题困惑着阿卷:”我从哪里来,我要到哪里去?“,阿卷为解开这些逻辑背后的真相,开始了C/C++后台的学习。
在C++后端的学习过程中,除了语言之外,Linux系统编程与网络编程是必不可少的内容。在学习Linux系统编程、网络编程的过程中,你将掌握与计算机底层、不同计算机、不同进程之间对话的技巧。不同于Java高度统一且完备的开发生态,C++服务器的开发则可由你自己来定义,市面上各个公司使用的开发框架都有所不同,开发曲线也较陡峭,但C++服务器的高性能特点,使得C++服务器的需求始终存在。
要求
- 实现客户端与服务端的回声通信,如客户端发送"AAA"给服务端,则服务端返回"AAA"给客户端。
学习要点
- C/C++基本语法
- 网络编程(Socket)基本概念
分支2 Task2:C/C++实现简易http文件服务器
在之前的任务1.1中,我们的服务器只是简单地将获取的数据返回给客户端,而并未对发送的数据进行解析。所以在任务1.1的基础之上,任务1.2需要学习一点HTTP的相关知识,了解浏览器发出的HTTP的请求,并根据请求发送对应的信息给客户端。
要求
- 可以部署在服务器,也可以在本地通过浏览器127.0.0.1访问。
- 如果访问的是文件夹,则展示文件夹中的文件,如果是文件,则文件展示内容。
学习要点
- C/C++基本语法
- Linux系统编程和网络编程基本
- HTTP协议
分支2 Task3:C/C++实现简易的WebServer
有了前面的学习经验,简易的通信流程想必已经了然于心,然而前面的服务器只实现了基本的需求,而对于实际的使用和生产需求则远远不够,所以在此基础上,可以参考网络上十分流行的C++项目(烂大街的)TinyWebServer,实现一个较为完整的C++的web服务器。实现一个简易的可登录、请求文件的web服务器。
要求
- 需要尽可能地包含服务器的基本功能,如日志管理器、线程池、数据库(可以只包含ID数据)等。
- 使用Webbench进行测试并发性能
学习要点
- C++ 11新特性、STL
- 了解数据库基本概念
- 多线程、I/O多路复用(select、poll、epoll)
C/C++后台开发所需的前置知识较多,系统学习的周期较长,但招新的目的仅为考核大家的学习能力与兴趣,大一的同学可以先整体了解知识体系,后续再系统学习,尽可能多的完成任务。而大二的同学则可以了解更多其它的内容,如libevent、muduo、分布式系统、Nginx中间件等的学习。
参考资料
书籍:C++ Primer Plus 、UNIX环境高级编程 、TCP/IP网络编程 、 Linux高性能服务器编程
提交内容
Task0
- 控制台的服务器信息截图
- 记录了学习Linux基本指令的markdown文件
Task2-4
-
源码上传到Github
-
记录学习过程的markdown文件,其中有源码链接
#7Compiler
前言
计算机体系结构是一个庞大并且复杂的学科方向,可能大部分人在学习的路上都会遇到很大困难、不解。但是焦糖的学长希望你能记住下面这些话:计算机的所有东西都是人做出来的,别人能想的出来,你也一定能想的出来,这里面也没有黑魔法,你目前的不明白不清楚,只是因为你不知道这个知识的前置信息。下面的所有题目只是计算机体系结构的冰山一角,如果你阅读完整个题目后觉得自己对于这个方面非常感兴趣,可以到 CS自学指南 进行更深入的学习,或者通过招新题进入工作室的方式获得学长更加细致化的指导(墙裂建议)。下面的所有题目并不要求全部做完,你的努力我们都看在眼里(看在你的md文档里),所以不论题目完成到什么程度,请务必将你的学习过程和目前进度发送给我们,Respect!
开始
这将是一次伟大的冒险。编译器(Compiler)拥有无限的探索和应用空间。你可以与他人分享编程乐趣或者只是自娱自乐。许多杰出的计算机科学家和软件工程师一直在这个领域探索,终其一生乐在其中。如果你是第一次接触这个领域,欢迎你!
本节将引导你参观编译世界。但在我们开始之前,需要先了解要踏足的土地。接下来,你需要了解编译器中的常用概念和这些概念的组织方式。
背景介绍
小黄是一个编译器初学者,他首先要做的事情一定是了解编译器(compiler)是干嘛的。按照以往的经验,他打开了b站,搜索关键词
compiler, 映入眼帘的——Make a compiler \ Stanford CS 143 Compilers …,小黄脸都绿了,作为一个编译器小白,里面的专有词汇太难懂了,小黄继续寻找着,直到发现 编译体系漫游, 内心os:实在讲的太好了捏,图文并茂,墙裂推荐。
TASK1
看完上述科普向视频,相信你已经记下了大量的笔记,大概能对编译器是干嘛、编译的流程、现在市面上有哪些编译器(编译器框架)有一个大概的了解,请在你的提交文档中包含但不局限于以下几个问题:
- 什么是编译器?编译器的大致工作流程是怎样的?
- 编译器前端的主要任务是什么?
- 编译器中端的主要任务是什么?
TASK2
学习编译的最好方式当然是 直接套用别人的项目 自己动手写一个编译器,但是从0实现一个完整的编译器又是一个任务量巨大且十分困难的工程,更不要说实现一个优化性能超强、拓展性极好的编译器了。一般来说,大家编译器入门的第一个小项目应该是实现一个支持四则运算的编译器,这其中涉及到根据我们所给定的文法来实现特定的功能。
考虑到实现难度问题,当然是不会让你手搓编译器前端滴,那简直是效率又低,还没有我们自动化工具方便。
我们需要依托Flex、Bison工具来完成我们的编译器。
在开始之前,你需要了解:
- 什么是Flex、Bison?
- 什么是文法,有哪些文法?
要求实现:
- 实现支持加减乘除运算的整数计算器,实现正确的计算优先级
- 实现使用括号来提升优先级 例如
2*(3+2) - 根据下面的表达式拓展Flex、Bison程序
实现下列的表达式:
(a ++ b) ::= a + (b + 1)
(a &* b) ::= (a & b) * b
(a |* b) ::= (a | b) * b
Eg:
输入:1 ++ 2
输出:4
选做内容:
- 实现浮点数的计算
- 发挥你的想象力实现任何计算器可以实现的功能
参考资料:
TASK3
敲!RISC-V!
RISC-V has rapidly emerged as the leading standard Instruction Set Architecture (ISA) in the world of processor design and implementation.
—— Calista Redmond, CEO, RISC-V International
在编译器的后端,我们需要针对目标机器的架构生成对应的汇编代码。(那么多种架构,我到底要做哪种???)在这节呢,我们需要针对RISC-V架构的目标机器来生成RISC-V汇编代码。可能读到这里你想到完成这道题目既需要完成编译器前中端,又需要从零开始写编译器后端,想想就头大!!!嘿嘿其实要小黄在这么短时间搓出一个完整的编译器前中后端也不是很现实的。本题只需要你完成很简单的任务,以此来了解一下RISC-V汇编即可。
题目内容:
-
配置环境:由于我们的笔记本电脑大多都是arm/x86环境,所以我们需要一个RISC-V,编译RISC-V完整工具链,并且配置qemu RISC-V环境模拟器。
基于RISCV工具链和环境,你可以尝试整个从编译源文件到运行可执行文件的所有步骤,由于工具链不同,命令可能不同,在此只给出一个示范:
# 得到RISCV汇编文件 riscv-unknow-elf-gcc -S -o test.s test.c # riscv-unknow-elf-as -o test.o test.s # 生成可执行文件 # “[ ]”中内容是可选项 riscv-unknow-elf-gcc -o test test.o [library.c] -lm # 执行 qemu-riscv64 test [< test.in] # 查看返回值 echo $? -
了解RISC-V汇编语言程序,你需要关注的点包括但不限于:寄存器,堆,栈,指令。
-
根据给出的参考资料以及自己从网上搜寻的资料,使用RISC-V指令集实现降序冒泡排序程序,给出必要部分即可。
-
(选做)尝试在qemu模拟器中调试你自己的riscv汇编
参考资料:
TASK4-1 IR & SSA & CFG
小黄在了解了基础的编译器知识后,对于编译器越发的感兴趣,偶然间得他得知了LLVM项目,于是开始下定决心学习,励志早日成为LLVM contributor…
在看过了编译体系漫游 之后,小黄对编译体系有了一个系统性的认识。在编译的过程中分为了几个步骤,首先编译器前端会对你的代码进行解析(大家在TASK2用到的flex和bison就是前端解析的其中一种工具),最终会形成中间代码IR(Intermediate Representation),这个中间代码又是什么鬼?为什么会设计出中间代码这个东西捏?而不是直接前端到汇编这样直接翻译?
大家不妨可以想一想,如果我有三种高级语言(c,c++,Rust),对应需要翻译到3种汇编语言(arm,riscv,x86),我们需要写几个编译程序,3x3=9个是吧,所以聪明的编译器工程师就想到了一个办法,设计一个大家统一的中间代码,无论你的前端高级语言是什么c,c++,我都会将他翻译成统一的中间代码格式,再由这个中间代码分别翻译到最终的目标代码,那算一下我们我们是不是只需要实现3+3=6个程序,工作量确实变少了
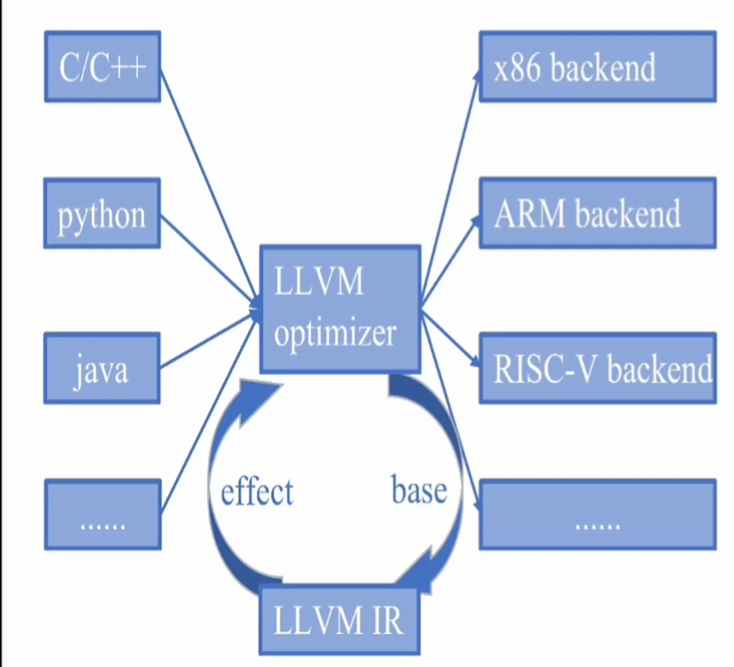
而这只是使用IR的其中一个好处,IR使用的更大目标是更加方便的对程序进行优化(后面我们会慢慢涉及,不要着急哦~)
初步了解完什么是IR之后,再来看看SSA(也叫静态单一赋值形式),其实SSA可以简单理解为是IR可以具备的一个特性,同时拥有SSA性质的IR中间代码
我们来看看什么是单赋值,其实很简单,这里以一个C代码为例进行说明
int main(){
x=1;
y=x+1;
x=2;
z=x+1;
}
在这一个代码中,我们可以看到x实质上是进行了两次赋值,而SSA的特点是单赋值形式,所以为了将他修改成符合SSA形式的代码,只需要引入一个版本信息
int main(){
x1=1;
y1=x1+1;
x2=2;
z1=x2+1;
}
这就是正确的SSA形式(很简单吧
SSA带来的好处也非常明显,通过引入版本信息的方式将同一个变量划分到不同的作用域,我们很容易能完成一些非SSA形式下很难做到(相比SSA形式算法实现复杂度会更高)的优化,就具体的这个例子来说,引入SSA后我们可以很轻易的发现x1是没有任何user(y1就是x2的user),那我们可以直接将x1=1这一条语句进行删除,进一步的优化代码结构和删除冗余的指令
int main(){
x1=1;
x2=4;
y1=x2+1;
}
在了解透彻上述内容之后,小黄也算是登堂入室,同时他非常好奇编译器是以什么载体来表示一个程序中IR的逻辑关系,于是这就不得不提到我们的CFG—控制流图(大一的萌新可以先了解一下图这个数据结构哦~)。
在编译器的中端表示中一般是以图的方式来描述程序的所有可能执行的方式,同时为了简化CFG,又引入了Block的概念,什么意思呢,别着急,还是以一个例子来看看
int func(int y) {
int x = 12;
if (x < y) {
y = 0;
x = x + 1;
} else {
x = y;
}
return x;
}
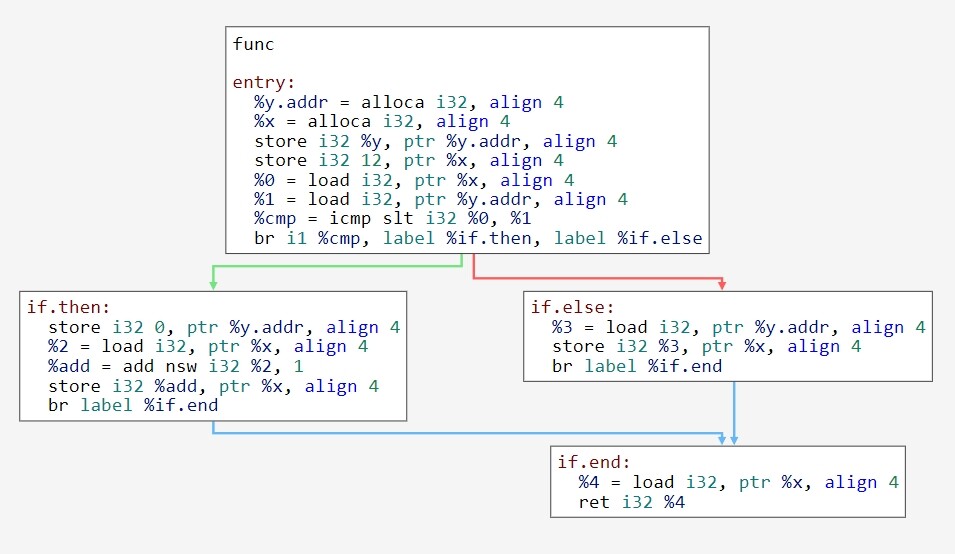
可以看到这每一个大的块就是一个Block,每个Block里存在着一系列的指令,不同Block之间的边代表了数据的流向关系(图中if-else语句会导致数据流产生分岔)。
编译器利用控制流图来表示指令间的次序关系和数据的流向关系,在一些需要跳转的指令中(比如if else 、while循环),Block会创建两个出边(基本图论定义与术语)用来表示可能的数据流向关系,而在我们的中端也是基于CFG这样的图结构来进行优化(大二经历过卓中卓考核的同学应该实现了支配树等算法,类似这样的支配分析也是基于CFG图优化的一个非常重要并且基础的结构)
题目内容
- 请你了解IR中φ函数的作用,并将你所了解和你自己的思考写入Markdown文档中。
- 尝试了解目前存在哪些SSA形式(SSA形式也是有很多变种滴),了解他们设计出来的目的。
- 尝试编译LLVM12.0(bonus!)或者使用在线编译平台 GodBolt(一个十分有用的网站),结合学习到的SSA知识查看LLVM的中端IR表示形式,了解LLVM IR的基本语法(不需要知道过于复杂的,建议在学习完前面的堆栈寄存器知识后食用!毕竟llvm一开始是假设所有的变量全在栈上)
TASK4-2
小黄在学习完LLVM的IR表示后,又发现了其中一个极其重要的数据结构…
相信你已经成为了一个了解LLVM中IR中间表示的童鞋,下面我们要探索LLVM中最核心的设计之一:Value 、User 、Use,LLVM中几乎所有的中端优化都需要围绕着这个设计来展开,
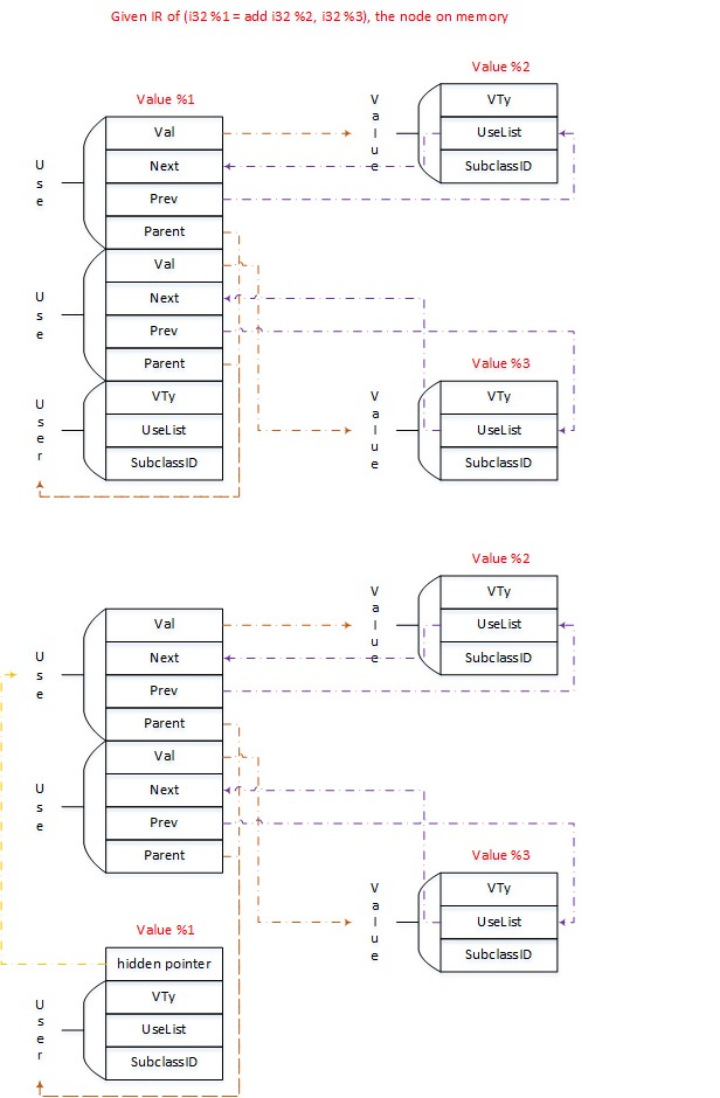
理解了这一套内存表示关系就掌握了LLVM中非常核心的部分,同时中端的所有优化都是基于这一套关系来进行的。同样我们举一个例子来进行说明
int main(){
int a, b0, _c;
a = 1;
b0 = 2;
_c = 3;
return b0 + _c;
}
//经过前端处理翻译到中端IR
define i32 @main(){
.1:
%.4 = alloca i32
%.3 = alloca i32
%.2 = alloca i32
store i32 1, i32* %.2
store i32 2, i32* %.3
store i32 3, i32* %.4
%.11 = load i32, i32* %.3
%.12 = load i32, i32* %.4
%.13 = add i32 %.11, %.12
ret i32 %.13
}
对于%.4来说,%.4通过alloca指令开辟了一段栈空间来存放,store i32 3, i32* %.4和%.12 = load i32, i32* %.4这两条指令的操作数用到了%.4,所以在结构上我们就认为这条store指令和%.12是%.4的user,%.4是store指令和%.12的usee,那么如何通过一个有效方便的数据结构来表示呢,Use便呼之欲出了
通过一个Use类,我们可以把Use当成图的一条边,Use中记录了User和Usee(被使用者,对于上述例子来说就是%.4),同时我们可以在每个指令类中设置一个UserList和UseList,分别记录这条指令的所有User和Use(这里指使用到的指令而非数据结构Use),采用这样的数据结构关系有什么好处捏?可以设想一个加法指令,如果我们得知他的UserList为空(即无人使用),那是不是说明这一条指令在逻辑意义上是dead?当然死代码的判断还需要一些约束条件,但是主要的思路也是大差不差了
如果你想要更加深入的了解这一结构(比如你想要手搓一个)深入浅出 LLVM之 Value 、User 、Use 源码解析 或许会帮助你
题目内容(本题为可选项):
请你了解以下内容
- 什么是 Value 、User 、Use,他们之间的关系是怎样的?
- User是如何维护Usee、UseList的
- Use和Value、User的关系,以及它是如何维护这个关系的
- 记录在Markdown文档中
参考资料:
TASK4-3
小黄在经过了SSA和Use-def关系的Buff加持后,实力突飞猛进,已经可以进一步的尝试一些基础的中端优化了
在了解了LLVM IR 和 Value、User、Use之后,我们是一定需要对这些知识有一个总结性的应用的,思考一下我们还有哪些部分没有涉及到呢?没错,中端优化!下面我们需要了解并且实现两个很基础的优化——ConstantProp、DCE(DeadCodeElimination)。
DCE死代码消除
考虑到下面一段程序:
int main()
{
int a = 1, b = 2, c = 3;
int d = a + b;
c = a + c;
return d;
}
//经过前端处理翻译,经由mem2reg优化后的IR
define i32 @main() #0 {
%1 = add nsw i32 1, 2
%2 = add nsw i32 1, 3
ret i32 %1
}
在这段程序当中,User %2 (这里我们为了方便将每一个Inst称为User,后续代码的实现也是如此)的UserList为空,并且其没有任何的SideEffect(SideEffect是指一些特殊的指令,比如说对于Store指令,他是没有任何User的,但是Store语句本身的作用让他不能被删除,因为被删除了那么一个赋值指令就没了,会对整体的代码运行产生影响),说明这一条指令在逻辑意义上是死代码,可以删除
后续的实现需要额外注意一下这个这个SideEffect的判定,哪些指令属于是SideEffect的?
于是main函数这段IR我们可以优化为
define i32 @main() #0 {
%1 = add nsw i32 1, 2
ret i32 %1
}
// 它对应的C语言程序就为
int main()
{
int a = 1, b = 2, c = 3;
int d = a + b;
return d;
}
这可以很大程度上优化代码体积和代码运行效率。
下面我们会向你提供一个完整的编译器前端部分(其中已经帮你实现了mem2reg,你只需要实现对应函数),详细可见 JoTang Compiler,部分内容已经帮你实现,请你补全TODO部分(Vscode上安装插件ToDo Tree能够快速的看到存在的所有TODO注释)。
要求实现:
//Frontend_Compiler/ir/opt/DCE.cpp
bool HasSideEffect(User* inst);
void RemoveInst(User* inst);
bool Run();
请你考虑:
- 如何判断一个Instruction是否为DeadInstruction
- 如何删除一个Instruction,这个过程中需要维护什么?
- 本优化默认你不会处理含有数组的C文件,完成这样的基础优化后你可以考虑一下对于数组的处理(了解Gep指令)
请将你的思考记录在Markdown文档中
ConstantProp常量传播
这是一个优化效果十分显著并且实现相对简单的优化,考虑到下面一段程序:
int main()
{
int a = 1, b = 2, c = 3;
int d = a + b;
return d;
}
//经过前端处理翻译,经由mem2reg优化后的IR
define i32 @main() #0 {
%1 = add nsw i32 1, 2
ret i32 %1
}
在这段程序当中,User %1 的UseList都为常数(ConstIRInt),这条add指令的User可以被一个常数代替,这段程序我们可以优化为
define i32 @main() #0 {
ret i32 3
}
// 对应的C语言程序为
int main()
{
return 3;
}
设想一段程序,有好多条类似%1的指令,那这个优化的效果就十分显著了。
要求实现:
//Frontend_Compiler/ir/opt/ConstantProp.cpp
Value* ConstFoldInst(User* inst);
bool Run();
请你考虑:
- 一个Instruction的所有User是如何被替换为一个新的Value的?(在代码中我们为你提供了相关的实现)
- 什么情况下不能将一个操作数都是常数的指令化简?
- 本优化默认你不会处理含有数组的C文件,完成这样的基础优化后你可以考虑一下对于数组的处理(了解Gep指令)
请将你的思考记录在Markdown文档中
TASK5
首先恭喜你!艰难且顺利地完成了前面的任务!相信在有了坚实的基础后,你已经对编译器的总体设计和LLVM的基本架构有了自己的认识!你可能疑惑过,为什么LLVM IR 和 RISC-V汇编代码会有一些差别?在中端的LLVM IR中,其实我们是基于了一个假设,即寄存器的数量是无限的,所以你会看到dump出的IR中会出现%.1、%.5…%.1732等等,但是实际上寄存器的数量是有限且十分珍贵的(相比于从内存中取出我们需要的内容,如果把他直接放在寄存器上我们取出,二者的时间会相差很多,如果较为感兴趣可以去探索一下指令周期之间的差异,所以如何正确的并且高效的分配寄存器是编译器后端一个十分重要的问题 )
Tips:
内存和寄存器分别在计算机中扮演着不同的角色,内存提供给我们超大的存储空间,但是访问的速度会较慢,而寄存器一般位于CPU的内部(可以说是近水楼台先得月了),CPU通常能够以很快的速度访问一个特定寄存器的内容,下面我们模拟一个待取数据分别在内存和寄存器的情况来对这二者的关系进行一个对比
//我们以这一条指令为例
%3 = add nsw i32 %1, %2
//ir => 汇编(未进行寄存器分配,还是以虚拟寄存器的形式存在)
add %.3, %.1, %.2
假设此时我们正准备取%.2的值,待取数据%.2存放于一个寄存器中
add %.3, %.1, a6 //a6表示riscv架构的一个寄存器
当CPU知道待取值位于a6寄存器后,CPU直接通过指令访问这个寄存器,无需额外的地址信号,数据立即从寄存器中读取,这一过程几乎能在一个指令周期完成
下面我们再来看看如果%.2位于内存,与前者不一样的是CPU会先发送地址信号到内存控制器中,由内存控制器找到待取数据对应的内存单元并取出到一个寄存器,再执行我们刚刚谈到的过程,也就是说,与待取数据直接在寄存器相比,我们多了一个load操作(内存值load到寄存器),而因为增加了一条load指令并且需要操作系统访问虚拟内存,所需要的指令周期大大增加(由于架构的限制,目前大多数现代处理器规定只能操作寄存器中的数据,所以这里我们首先需要load到寄存器中再进行后续操作)
lw a6, offset(%base)
add %.3, %.1, a6
而%.2是否是在内存(可能刚好没有足够的寄存器来承载%.2会导致其spill到内存)或寄存器通常是通过我们寄存器分配决策而定,就像俄罗斯方块一样,一个合理的策略能更好的利用不同的寄存器。
我们不会让你去实现寄存器分配,毕竟实现寄存器分配是一个需要考虑目标平台架构的工作,本节的任务需要你了解寄存器分配通用的算法,并阅读给定的论文,从中提炼你认为关键的信息即可。
题目内容:
了解以下内容
-
什么是线性扫描和图着色算法,这两个算法是如何应用在寄存器分配的?
-
阅读论文 Iterated Register Coalescing(更多Ref:虎书查找第十一章 寄存器分配,寄存器分配4:改进的线性扫描寄存器分配)
请将你的思考记录在Markdown文档中
提交内容:
- 所有的程序源代码(需要上传到GitHub仓库,提交时提交链接)
- 你的Markdown文档
考虑到我们的题目难度可能偏大,所以最终没有完全实现也是没有关系的,重要的是你这一路的学习理解过程,请务必记录在你的markdown文档中!
如果有佬全部实现这两个优化Pass并且对于这一方面感兴趣,欢迎随时联系出题人:lyh552506 (wechat)
#8机器学习
Task 0: 机器学习入门
背景介绍:
在人工智能的世界里,机器学习是一颗璀璨的明珠。它让机器能够从数据中学习,从而做出智能的决策。本任务旨在引导新生们初步了解机器学习的基本概念和应用。你的入门学习路线大致为:数学基础、编程基础、机器学习基础。
数学基础:微积分、线性代数、概率论(大一的小东西不要紧张!!!这只需要你对以上内容的概念、在机器学习里起到的作用大致了解即可,不用预习整门课学习计算)。重点去了解偏导数、链式求导、梯度计算、矩阵运算和线性变换。推荐书目《深度学习的数学》第二章,视频可参考深度学习的数学这个合集视频的前两章。
编程语言基础:Python。你可以通过文档、网课来学习。文档可参考Python教程 - 廖雪峰的官方网站 ;网课在B站找播放量较高、时长相对短的即可。这一部分不要花太多时间,浏览一遍,两天左右即可,没有编程基础的同学不要担心,以后在具体的项目代码中你会发现前面看的教程一点用都没有可以一边查阅资料一边学习。
机器学习基础:机器学习基本概念、Pytorch框架。推荐视频吴恩达机器学习,看前几节了解基本概念即可;Pytorch入门教程,可以快速了解并上手Pytorch代码框架。
Tips:理论知识学习过程中如果遇到不明白的部分,记得善用GPT以及Google搜索等工具~你的问题基本都能在博客、论坛或GPT回答中找到解决方案。
本题要求:
- 阅读观看推荐的资料,了解机器学习的基本概念。
- 将相关学习笔记整理成Markdown文件,包括但不限于以下内容:
- 监督学习与无监督学习的区别
- 机器学习和深度学习的区别
- 偏导数、链式法则、梯度、矩阵等数学概念在机器学习中的作用
- 常见的激活函数
- 神经网络的基本结构
- 机器学习中的数据处理
- Markdown文件的具体结构框架自行拟定,最终呈现内容的逻辑性是打分的重要依据。
- 本题建议的学习与作答时间为一周。
提交内容:
- Markdown笔记:记录你的学习过程和理解,具体内容包括但不限于上面有提及的内容。
-
GitHub链接:将上述内容整理到一个名为
机器学习task0的文件夹中,并上传至GitHub。
机器学习的世界广阔而深邃,不要担心一开始无法完全理解,重要的是持续学习和实践。
Task 1: 波士顿房价预测
一番理论学习过后,相信你已经对机器学习有了一定理解,那我们就趁热打铁,进入实战模式,先来一道经典例题!
背景介绍:
在机器学习中,回归问题是一种预测连续数值的任务。波士顿房价数据集是一个经典的回归问题数据集,它包含了波士顿周边地区房屋的各种属性,如犯罪率、房屋平均房间数等,以及房屋的中值价格。本题要求使用PyTorch框架来构建和训练一个神经网络模型,以预测房价。数据集可从Kaggle波士顿房价数据集下载或自行采用其他方式。
本题要求:
- 使用PyTorch框架构建一个神经网络模型。
- 对数据进行预处理,包括归一化、处理缺失值等。
- 训练模型以预测房价,并将其分类到不同的价格区间。
- 评估模型的性能,并尝试调整模型参数以优化结果。
作答提示:
-
数据预处理:
- 加载波士顿房价数据集。
- 探索数据,了解各个特征的含义。
- 对数据进行清洗,处理缺失值和异常值。
- 对特征进行归一化处理。
-
模型构建:
- 设计一个适合回归问题的神经网络结构。
- 选择合适的损失函数,如均方误差(MSE)。
- 选择合适的优化器,如Adam或SGD。
-
模型训练:
- 将数据分为训练集和测试集。
- 训练模型,并使用验证集进行模型选择和超参数调优。
-
模型评估:
- 使用测试集评估模型的性能。
- 分析模型的预测结果,包括准确率、误差等。
-
结果分析与报告:
- 记录模型训练过程中的关键指标,如损失值和准确率的变化。
- 分析模型在不同价格区间的预测效果。
- 撰写实验报告,总结模型的性能和可能的改进方向。
提交内容:
- 代码:Python文件,内容为实现的神经网络模型代码,包括数据预处理、模型定义、训练和测试。
- 实验报告:使用Markdown文件记录你的实验过程和结果分析,包括模型结构、训练过程、结果评估等。
- GitHub链接:将上述内容整理到一个名为 “机器学习task1” 的文件夹中,并上传至GitHub。
Task 2: 嗨嗨的摄影图像分类
背景介绍:
计算机视觉是人工智能和计算机科学的一个分支,旨在使计算机能够通过处理和分析视觉数据(如图像和视频)来理解和解释现实世界中的场景。它涉及从低级别的图像处理(如边缘检测和图像增强)到高级别的场景理解和物体识别。
题目要求:
嗨嗨是一个喜欢在野外采风的小男孩,他拍摄了许多照片,其中包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。但是迷糊的嗨嗨的摄影水平比较普通,他拍摄的照片有的很不错,有的模糊不清,希望你能利用计算机视觉的知识,设计并实现一个model进行分类,最终实现对图像类别的准确预测。
- 根据给出的代码框架,补全网络部分的代码,尽力提高自己的分数吧。
注:数据集的图像尺寸为32x32,并且已经分为50,000张训练图像和10,000张测试图像。代码框架地址链接:我是框架
进阶要求:
1.你是否尝试可视化你的训练准确率和loss,画一张图来看看他们的变化曲线吧。
2.发挥你的奇思妙想,查找资料,是否有其他策略提高准确率?指出你的策略和在源代码中的修改。
作答要求:
- 提供你的task.py代码,其中包含你的注释(可以根据自己的理解对代码框架进行注释),你的代码运行结果截图。如果你完成了进阶任务,新建一个命名为task_extra.py的文件进行提交
- 记录你的代码实现思路,遇到的困难以及你的解决方案,以markdown形式提交.如果能够完成进阶任务,也在markdown中记录下来你的思路
- 所有作答均放到名为 “机器学习task2” 的文件夹里,提交代码和markdown文件
做题策略:
1.做题前,你可以尝试思考如下的问题,简单记录下你的回答:
-
计算机采用什么数据结构存储、处理图像?
-
如何设计一个神经网络?一个神经网络通常包括哪些部分?
-
什么是欠拟合?什么是过拟合?
1.conda是一个开源的软件包管理系统和环境管理系统,它主要用于安装多个版本的软件包及其依赖关系,并能轻松地在它们之间切换。建议你使用anaconda创建你自己的环境进行环境管理。
2.我们强烈推荐你在这个任务里使用GPU,当然这个任务里CPU也是可以用的。不过后面的任务如果没有GPU是非常难搞的。
你可以使用以下平台获取算力:
kaggle(每周免费30小时)、modelscope魔搭社区 (新用户36小时免费,后续收费)、AutoDL(需要一点点money)、阿里云(新用户有免费额度、后续收费)
3.先了解前面task的前置知识会帮助你更好的解题,可以参考这一教程pytorch深度学习实践了解pytorch的用法和卷积网络。如果你想了解cv领域其他有趣的任务分支,可以去看这位赛博导师主页的讲解视频:cv常见任务讲解
Task3 论文阅读:Vision Transformer (ViT)
写在前面:
这个任务比较有难度,我们鼓励大家尝试,没有完成也不要灰心。这个任务不是必须全部完成的,你也可以记录你在这个过程中遇到的问题和思考。同时,完成代码复现之前,确保你有且有足够的GPU(不会cuda out of memory)
题目要求:
1.阅读并深入理解 Vision Transformer (ViT) 论文,以学习笔记的形式记录。包括但不限于架构分析,关键技术创新点等
论文链接:Vit论文链接
2.ViT和CNN相比有什么区别?比较ViT和CNN的异同和优缺点记录在学习笔记里。
3.ViT 模型的实现与实验
- 实现要求:
- 基于 PyTorch 实现 ViT 模型(可以使用已有的库如 timm 来实现)
- 使用 CIFAR-10 数据集对 ViT 进行训练,并与传统的 CNN 模型(如 ResNet-18、VGG-16)进行对比
- 分析 ViT 在 CIFAR-10 数据集上的表现,并记录实验结果(训练时间、最终准确率、收敛速度等)
- 实验结果分析:
- ViT 的性能与 ResNet-18 等 CNN 模型相比有何不同?是否如预期表现较好?为什么?
- 对比使用不同 Patch Size 的 ViT 的表现,分析 Patch Size 对模型性能的影响
注:你可以参考论文作者的代码仓库进行复现
做答要求:
提交代码和markdown文件(不需要所有任务全部完成,也可以只提交markdown)
所有作答均放到名为 ”机器学习task3“ 的文件夹里
Task4:TrustWorthy LLM–Context Watermark
背景介绍
近年来,大型语言模型(LLMs)的快速发展催生了众多优秀的研究成果,包括开源项目如LLaMA和Falcon,以及商业产品如GPT-4和Gemini。这些进展推动了自然语言处理领域的范式转变,不仅在传统的NLP任务(如问答系统、翻译和信息抽取)中取得了显著进展,还展示了在代码生成等领域的新能力。
然而,随着LLMs在各个领域的不断测试和应用,研究人员发现其输出并不总是准确的。这些错误输出主要分为两类:幻觉和错误信息。幻觉(hallucinations)指模型生成的内容完全虚构,看似合理但实际上不存在。错误信息(Misinformation)则指模型生成的包含错误或不准确信息的内容,这可能源于模型对问题的误解或依赖不正确的训练数据。因此,错误信息是一个比幻觉更广泛的概念。这些错误输出可能削弱LLMs在关键应用中的实用性,并引发其在实际场景中负责任部署的担忧。
由LLMs生成的错误信息可能导致严重后果,例如操纵公众舆论、制造混乱和传播有害意识形态。尤其是在COVID-19疫情等敏感时期,错误信息加剧了恐慌和误导。幻觉和错误信息带来的危险多种多样,并且对现实世界产生影响,凸显了解决这一挑战的重要性。
错误信息通常分为两类:有意错误信息(Intentional Misinformation)和无意错误信息(Unintentional Misinformation)。有意错误信息通常源自恶意人为操控模型生成特定的错误信息,而无意错误信息通常源于数据或模型的局限性,幻觉被认为是这一类别的子集。研究表明,幻觉来源于多种因素,包括数据质量问题、偏见、过时信息以及模型训练和推理策略的局限性。内在幻觉是指模型输出中的自相矛盾,而外在幻觉则表现为无法根据输入数据验证的输出。
研究人员一直在努力理解这些原因并开发缓解策略,例如面向事实的数据集、自动数据清理技术、检索增强,以及旨在提高事实准确性的新模型架构和训练目标。
为了对抗幻觉加剧的错误信息的传播,必须在LLMs的整个生命周期内实施预防措施,并开发检测方法以判断某些信息是否是由这些模型生成的错误信息。预防(Prevention)措施包括模型的内部和外部方法,分别影响训练推理阶段和用户输入阶段。检测(Detection)方法包括水印(WaterMark)源追踪和事实性检测,首先确定信息是否由LLMs生成,然后判断其是否错误。
NLP Basic Points
在开始本题的学习之前,需要学习和get的知识和技能点:
-
logits是什么?softmax函数是什么?
-
Attention机制
-
Transformer
-
LLM 基本架构(主要知道什么是自回归模型就好啦~)
-
可以在huggingface上面试玩几个开源的LLMs
本题任务(提交要求):
本题锻炼大家的论文阅读能力和实验复现能力。具体完成结果不固定,重点在于 解决问题的过程 和 个人的思考。(结果不重要,重点在过程!!)你可能会遇到很多报错,环境冲突也好,代码缺陷也好,都是很常见的,大家都是这样慢慢开始的。尽量详细记录学习过程和解决问题过程,即使最终结果没做出来,我们也能看见你的努力~
三个任务由易到难,大家尽力而为就好。你需要写 一份 记录了学习过程和你的思考(如果有)的 md文件 ,提交题目时,将md文件和代码打包,文件夹命名为" 机器学习 task4"
Task 4.1
阅读论文:A Watermark for Large Language Models
一边阅读论文,一遍学习上述知识点,整理学习笔记。希望能够在学习笔记中看到同学们自己的思考。尝试用自己的话去描述论文中所给出的两种水印算法(hard watermark)和(soft watermark)。学习论文中各种水印攻击方式,尝试思考这些攻击方式为什么会有效?
Task 4.2
复现论文实验:
- 这里推荐两种复现方式:1. 使用原作者给出的github链接做复现 2. 使用MarkLLM工具库 ,这是一个开源的工具库,里面整合了许多水印添加与检测的方式。
- 将你认为重要的函数作用进行注释
- 如果能成功地运行源码,在md文件中附上运行结果的截图: 在1%FPR下的ACC, TPR, FNR, TNR,F1 score
- 再说一遍,最终没有成功跑起来也没关系,在md文件中详细记录你的 学习过程 和 解决问题的过程 ,出题人会看到你的努力!
Task 4.3
继续思考:这篇论文的水印做法的缺陷在那里?如果有,请写入md文件。
#9数据库题目
01背景介绍
话说那晚月黑风高,小坏同学躺在宿舍冰冷的床板上,横竖睡不着,决定夜访数据库,卷身边人一个出其不意。他两眼放光,口中发出桀桀怪笑,双手伸向电脑,俨然一副痴人模样。
当你在浏览器上输入检索信息,按下回车键时,当你打开游戏创建角色时,甚至当你走进银行,刷卡取钱时,数据库,这个对信息系统进行数据管理的技术,就已经在影响你的生活了。
作为所有题目中最为简单的一道(我说的,没错)本题倾向于以实际使用的方式,带你简单了解一下关系型数据库的基本知识。假如你对这方面很感兴趣,可以在完成题目之余,参考在焦糖官网上学长以前分享的数据库学习路线,进行更加深入的学习。
02开始之前
小坏打开电脑,开始搜索教程,为自己的数据库之旅打上坚实基础
- 你需要自行选择一种关系型数据库(Mysql、Postgresql等),并且下载对应的 DBMS(数据库管理系统)软件以及相关管理工具
- 你需要自行上网搜索关系模型的相关知识,这有助于你理解接下来的题目,当然,假如你对于其他数据模型也很感兴趣,欢迎自主探索,可以将你学习的心路历程写在你提交的文档里,一同提交
- 你需要结合题目中给出的参考资料和网上的资源,自行学习 SQL 的基础语法(会用即可),同样,也鼓励进行自主探索
- 你可以选择在自己电脑中配置 JAVA 环境,并使用你喜欢的 IDE 完成后续部分题目。(大一的同学这里不做强制要求)
03初始尝试
小坏同学觉得自己已经准备好了,他脑筋一转,决定从身边的课程管理信息入手
- 你可以尝试自己设计一个课程管理系统的数据库模型,考虑每个实体之间的关系以及业务规则,明确表结构以及字段定义。也可以在下面提供的各表的字段定义的基础上完成后续问题
- 温馨提示:假如你选择自己设计数据库模型的话,可以选择使用 Power Designer 等建模工具帮助你整理思路,我也非常推荐你自行了解 E-R 模型以及概念、逻辑、物理数据库等数据库设计的相关知识,这都有助于你完善自己设计的数据库模型,当然,请确保你设计的数据库采用了关系型数据库的设计方式,并且满足 3NF 规范,以免后续题目进行时出现问题。
| 字段名称 | 字段编码 | 数据类型 | 字段大小 | 必填字段 | 备注 |
|---|---|---|---|---|---|
| 教师编号 | TeacherID | Int | 是 | 主键 | |
| 教师姓名 | TeacherName | Varchar | 20 | 是 | |
| 联系电话 | TeacherTel | Varchar | 11 | 是 | |
| 在职时间 | WorkingDate | Date | 是 | ||
| 所在学院 | TeacherDepartment | Varchar | 60 | 是 |
| 字段名称 | 字段编码 | 数据类型 | 字段大小 | 必填字段 | 备注 |
|---|---|---|---|---|---|
| 课程编号 | CourseID | Int | 是 | 主键 | |
| 课程名称 | CourseName | Varchar | 20 | 是 | |
| 教师编号 | TeacherID | Int | 是 | 外键 | |
| 课程类型 | CourseType | Char | 2 | 是 | 取值范围:上午、下午 |
| 开始日期 | BeginDate | Date | 是 | 默认日期设置为2024年1月1日 | |
| 结束日期 | EndDate | Date | 是 | 默认日期设置为2024年7月1日 | |
| 授课人数 | Student_Number | Int | 是 | 不能小于零 |
| 字段名称 | 字段编码 | 数据类型 | 字段大小 | 必填字段 | 备注 |
|---|---|---|---|---|---|
| 学号 | StudentID | Int | 是 | 主键 | |
| 学生姓名 | Studentname | Varchar | 20 | 是 | |
| 联系电话 | StudentTel | Varchar | 11 | 是 | |
| 专业 | Major | Varchar | 50 | 否 |
| 字段名称 | 字段编码 | 数据类型 | 字段大小 | 必填字段 | 备注 |
|---|---|---|---|---|---|
| 日志编号 | RecordID | Int | 是 | 主键 | |
| 学号 | StudentID | Int | 是 | 外键 | |
| 课程编号 | CourseID | Int | 是 | 外键 | |
| 选课日期 | EnrollmentDate | Date | 是 | 默认日期设置为2024年1月1日 | |
| 选课状态 | EnrollmentType | Char | 2 | 是 | 取值范围:成功、失败 |
- 根据以上给出的字段定义,或者你自己设计的数据库模型的段表定义,完成对于该数据库的创建以及数据处理,具体细节如下:
- 编写并运行 SQL 语句,创建数据库 DB(命名无要求,根据你的想法来即可),并在数据库中创建对应数据库表,并且定义其完整性约束。
- 你需要自己准备数据(每个表 3-10 条,内容无要求,请根据自己的情况选择数据量的多少),编写 SQL 语句将数据插入表中。
- 编写并运行 SQL 语句,查询在上午时段选择课程超过两门的的学生的个人信息。
- 编写并运行 SQL 语句,查询开始日期在 2023 年 1 月之后,课程类型在下午的课程信息(按照授课人数大小倒叙排列)
- 编写并运行 SQL 语句,统计 2023 年度上午时段各位老师的授课人数总和
- 创建SQL视图,通过视图查询指定学号下,该学生的选课信息(课程编号、课程名称、课程类型、教师姓名、日志编号、选课状态),并按照选课日期降序排列
- 温馨提示假如你选择自己设计数据库模型,你当然也需要自己设计查询语句来展现你在单表查询、Where 子句条件查询、内置函数使用、子查询处理多表、连接查询多表以及视图方面学习的情况。欢迎你探索更多 SQL 语句,你可以将你学习的内容详细地记录在markdown文档里,这将是你未来宝贵的资料
04再次尝试
小坏逐一尝试了学到的 SQL 语句,感觉数据库不过如此,于是他调转枪头,趁舍友没醒抓紧继续学点别的
相信你学到这里的时候,已经多多少少意识到了,SQL 语句仅仅是数据库技术中的一小部分,事实上存储管理、事务管理、并发控制、安全管理也是数据库技术中涉及的重要部分,而数据库编程作为编写运行在数据库服务器端的应用程序的技术,有助于我们进一步深入了解这些方面的知识。
- 在这个部分,你需要自主学习 MySQL 和 PostgreSQL 中存储过程、函数、游标的相关知识。在此基础上,你需要完成以下任务:
-
编写存储过程程序实现统计上一题中各个课程中选课时间晚于 2023 年 1 月的学生人数,然后在屏幕输出。(假如你是自己设计的数据库,那你就需要自行设计相应的的存储过程程序了)
-
编写存储过程程序,运用游标技术实现遍历教师表中的每一行数据,并且显示每位教师教授的课程信息以及选课的学生数量(假如你是自己设计的数据库,那么你设计的游标相关的存储过程程序至少要包含逐行遍历结果集中的每一行数据,并选择性地显示部分信息这一功能)
-
编写触发器程序实现在选课表中添加新记录时(不需要关心状态字段是否是“成功”,当然,欢迎你设计更复杂的触发器程序以实现检测,这并不困难),自动更新课程表中授课人数这一字段,在删除选课表中已有记录时,自动更新课程表中授课人数字段(当然,你可以选择完善对于“失败”状态的记录删除不用更新这一功能),假如你自行设计了数据库模型,那么你同样需要自行设计触发器的触发条件,例如你可以设计一个自己的日志表,用来记录在其他表被修改时的相关操作数据:如操作用户、修改时间、修改前数据、修改后数据等。
05后续部分
小坏困得眼皮打架,但是他还希望再多看点其他知识点,舍友就快起床了,他必须争分夺秒
- 这部分大一的同学不做强制要求,仅作了解即可
- 在完成了之前的任务后,我们终于来到了应用程序数据库访问编程和 JavaWeb 数据库访问编程。这两者都是后端技术中入门的部分,这里推荐大家尝试焦糖历年的后端题目,相信一定会有所收获。(特别是今年的,学到这里的你具有相当大的优势,嘿嘿嘿)
- 在本题中,你需要:
- 自主学习 JDBC 访问数据库编程技术,以及嵌入式 SQL 数据库访问编程技术,了解他们的基本语法以及通信方式
- 根据第一题的数据库,编写 Java 应用程序(请使用嵌入式 SQL 的 Java 编程方法)实现课程查询功能,即输入课程名称、教师名称、查询该课程的选课学生名单。(假如你是自己设计的数据库,那就需要你自己决定查询的内容是什么了,你需要将你对于此题所涉及知识的理解体现在你的文档上)
06参考资料以及要求
部分参考资料
提交方式
- 编写好markdown文档并且附上你的github项目地址
- markdown文档中包含做项目的学习过程和学习/编码的心得体会
- 详尽的项目部署运行方式
备注
-
本题的定位是新手向的数据库题目,主要目的还是在于考察大家在规定时间内对于数据库知识的掌握程度,因此希望你能够尽可能完善你的学习笔记,并将它体现在你最终提交的文档里。换言之,即使你没能够完成所有要求的题目,也能够凭借自己详实的学习记录,向我们展示你学到了什么。
-
本题目仅仅展现了数据库这门技术中的一小部分,假如你对这方面很感兴趣,可以在群里私聊我,也可以根据焦糖官网上学长分享的数据库学习路线进行进一步的学习。
-
在学习知识的时候,当然可以使用GPT等ai大语言模型,但我们希望你能够独立完成我们留下的题目,而不是把题目粘贴到搜索框,再把生成的答案粘贴到自己的仓库里。
-
面试不会问得很难,但会尽量问的全,所以不必因为某些部分难度太大而苦恼。
-
上面的参考资料并不一定能涵盖所有涉及的知识点,你需要自己搜索对应资料进行学习,如果你没有搜索思路,请试试看基础题里的搜索方法或者私信出题人。
-
欢迎群里提问,更欢迎私信丹砂出题人。
什么?后来小坏怎么了?后来啊,小坏看了很多代码,学了许多技术,但每当他回忆自己的大学生涯,总有一个月黑风高的夜晚闪烁在记忆深处。当然,还有被舍友抓包时惨绝人寰的场景。
#10网安
Part1 基础概念
在学习网络安全相关知识前,我们需要对计算机网络的结构和功能有基本了解。相信下面的题目可以帮助你快速掌握计算机网络相关的概念。请依据你所学习的知识,回答下面的问题吧~
第一部分:计算机网络基础
-
OSI七层模型
- 描述OSI七层模型的每一层及其功能。
- 举例说明在一次网页浏览过程中,数据如何在OSI模型中流动。
-
TCP/IP模型
- 比较TCP/IP协议栈和OSI模型的异同。
- 解释什么是IP地址、子网掩码和网关。
-
HTTP和HTTPS
- 解释HTTP和HTTPS的区别。
- 描述HTTPS协议如何保证数据传输的安全性。
-
DNS
- 什么是DNS?DNS如何工作?
- 解释A记录、CNAME记录、MX记录等常见DNS记录类型。
-
TCP和UDP
- 比较TCP和UDP的特点和使用场景。
- 解释TCP三次握手和四次挥手的过程。
第二部分:Python网络编程
-
HTTP请求
- 使用Python的
requests库发起一个GET请求,并输出响应的状态码和内容。 - 使用
requests库发送一个POST请求,并发送JSON数据。
- 使用Python的
-
套接字编程
- 使用Python的
socket模块编写一个简单的TCP服务器和客户端。 - 使用
socket模块编写一个UDP服务器和客户端。
- 使用Python的
第三部分:CDN(内容分发网络)
-
CDN概述
- 解释什么是CDN,以及CDN的主要功能和优势。
- 描述一个典型的CDN架构。
-
CDN工作原理
- 解释什么是边缘服务器、缓存命中率和回源。
- 描述CDN如何加速网页加载和视频流媒体传输。
-
CDN提供商
- 调查三个常见的CDN提供商(例如Cloudflare、Akamai、AWS CloudFront),比较它们的服务和定价。
推荐的学习资料:
- 学习与题目相关的知识即可:我见过的最好的计算机网络课程https://www.bilibili.com/video/BV11Z4y1R7Am/?spm_id_from=333.337.search-card.all.click&vd_source=54c0faccce4ad3cb5880ad6e9cbccab3
Part2 实战演练
经过Part1的洗礼,相信你对Python网络编程和CDN已经有了基本的了解。下面,让我们学习一篇CDN安全领域的论文,看看与CDN相关的网络安全漏洞形态吧。
论文链接:https://www.usenix.org/conference/usenixsecurity23/presentation/guo-run
请尽你所能复现其中的安全漏洞。